Changes made in Configuration Mode are effective after a restart of the MIRO application.
Configuration
Introduction
In this section you will learn how to customize GAMS MIRO. As you saw previously when creating your first app, MIRO launches without any further configuration. However, you will find that there are a lot of configuration possibilities to adapt MIRO to your specific model.
The configuration is done via a graphical configuration interface, with which you can create plots and widgets or change certain settings with a few mouse clicks, visually supported by a live preview. In addition, the configuration can also be done manually via a JSON file. In fact, all the graphical Configuration Mode does is create this JSON file.
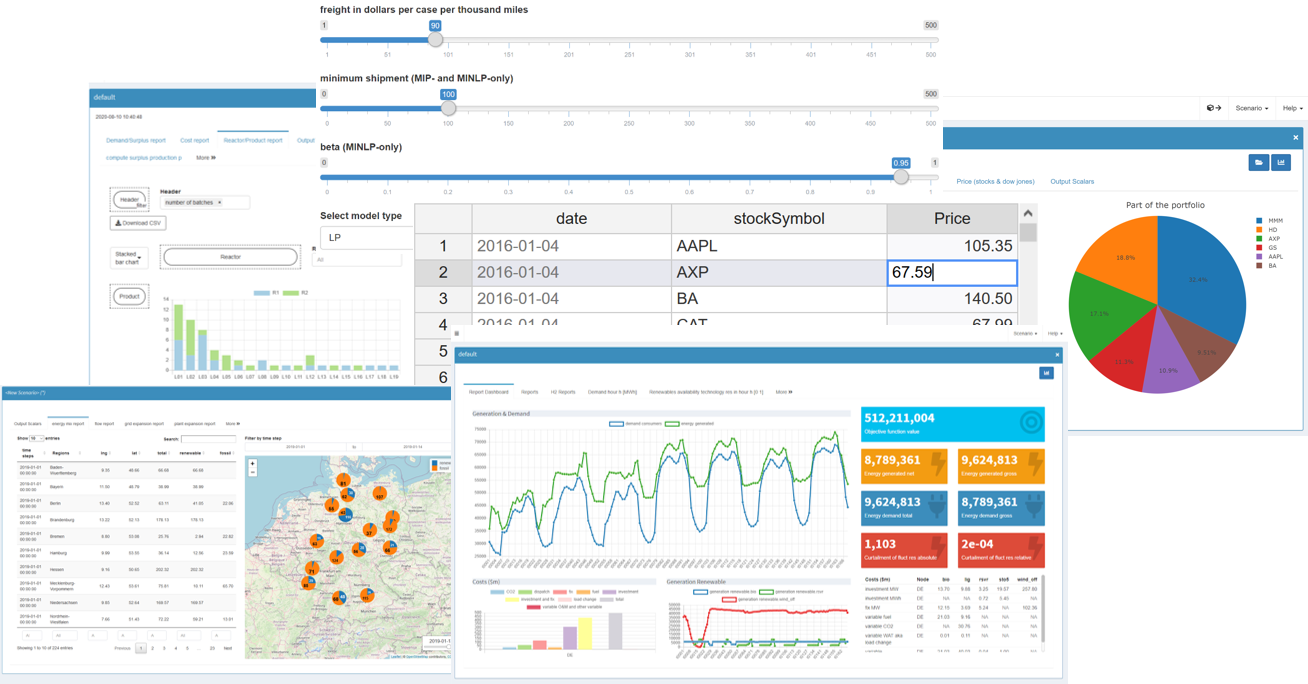
Configuration Mode
This chapter shows how to configure MIRO using the graphical interface. For those who feel more comfortable writing JSON, section Configuration via JSON shows how to configure a MIRO app without using the graphical interface.
The Configuration Mode is directly accessible via GAMS Studio:
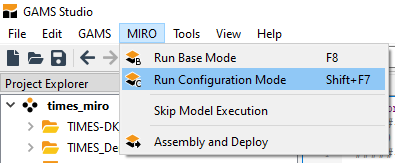
In order to launch the Configuration Mode via the command line, the environment variable MIRO_MODE=config needs to be set instead of MIRO_MODE=base. The other steps (see here) remain the same.
Note:
The Configuration Mode is categorized as follows:
Options not Available in Configuration Mode
With the Configuration Mode we pursue the goal that a user can completely configure a MIRO application without having to write any JSON code. However, there are a few advanced options that are not yet available in the Configuration Mode and will have to be configured manually. The following sections describe these options:
- Custom data connectors: Connect MIRO with external sources and exchange data in any format
- Custom input widgets: Create your own input widgets
- Dashboard scenario comparison: Configure a dashboard for scenario comparison
- Custom scenario comparison: Specify custom scenario comparison modules
- Drop-down menu in input table: Use dropdown menus instead of freely editable cells
- Column validation in input table: Validate manual edits by the user against predefined criteria
- Column width of an input table: Adjust the column width of individual tables
- Default Views in Pivot Compare Mode: Define a view that is shown first in Pivot Compare Mode
- Hypercube module: Widget groups: Group widgets in the Hypercube submission dialog
Advanced topics
The following more advanced topics are covered in subsequent chapters:
- Custom Renderers: Create sophisticated custom graphics
- Widgets with ranges: Widgets that return two scalars instead of one
- Dependencies among widgets: Define interdependencies between parameters
- Configuration via JSON files: Configure MIRO without using the Configuration Mode
- Language Files: Translate MIRO into another language