Table of Contents
CSV2GDX is a tool that reads a CSV file and writes to a GDX file. There are multiple ways to read [CSV] (https://en.wikipedia.org/wiki/Comma-separated_values) files (Comma Separated Values) inside GAMS (see Data Exchange with Text Files for instance), but a number of features available in CSV2GDX make it possible to read a CSV file where GAMS itself cannot be used. In addition to the syntax explanation and the basic functionalities demonstrated on some examples, this tutorial also discusses some advantages and disadvantages of CSV2GDX compared to the GAMS internal table statement.
- Attention
CSV2GDXis deprecated (see GAMS 48 CSV2GDX release notes). Please use GAMS Tool CSVRead instead.
Usage
CSV2GDX is called by specifying the CSV file and several options to define how to read the data.
csv2gdx filename {options}
The input file; the
.csvfile extension is assumed when no extension has been specified.Parameters can also be read from a text file; the use of an external file for parameters is indicated by preceding the file name with a @ (at sign). When reading parameters from a text file, lines starting with an asterisk (*) will be ignored. See also Example 8.
Options
The following options can be used when calling CSV2GDX:
| Option | Default | Description |
|---|---|---|
| acceptBadUels | N | Indicate if bad UELs are accepted or result in an error return code. |
| autoCol | none | Generate automatic UELs for each column. |
| autoRow | none | Generate automatic UELs for each row. |
| checkDate | N | Write GDX file only if the CSV file is more recent than the GDX file. |
| colCount | none | Number of columns in the input file. |
| decimalSep | Period | Specify a decimal separator. |
| fieldSep | Comma | Specify a field separator. |
| id | none | Identifier for the symbol in the GDX file. |
| index | none | Identify columns to get UELs from. |
| output | <CSVFilename>.gdx | Optional output filename. |
| password | none | Password for an encrypted input file. |
| storeZero | N | Indicate how zero values are handled. |
| text | none | Specify the column to get explanatory text from. |
| trace | 1 | Controls the amount of information written to the log. |
| useHeader | N | Indicate if the first row is a header row. |
| value | none | Specify the column to get the values from. |
| valueDim | N | Adds an extra dimension for values. |
| values | none | Specify the columns to get the values from. |
- Note
- The user has to specify an identifier for the symbol in the GDX file within the parameter
id, regardless of the data structure in the CSV file. CSV2GDXdetermines the number of columns in the CSV file from the header row or from the user defined input specified in the parametercolCount. Therefore, the user must enable the optionuseHeaderor has to specify the number of columns withincolCountin any case.
- The user has to specify an identifier for the symbol in the GDX file within the parameter
Some more detailed remarks on the options:
acceptBadUels = boolean (default=N)
This option specifies how to proceed, when a bad UEL (e.g. too long) is encountered. If set to
N, reading is stopped, and an error is signaled. When set toY, a valid UEL is made up and reading is continued.
Generate automatic UELs for each column. The autoCol string is used as the prefix for the column label numbers. This option overrides the use of a header row. However, if there is a header row, one must skip the row by enabling
useHeader. This option is demonstrated in Example 3.
Generate automatic UELs for each row. The autoRow string is used as the prefix for the row label numbers. The generated unique elements will be used in the first index position shifting other elements to the right. Using
autoRowcan be helpful when there are no labels that can be used as unique elements but also to store entries that would be a duplicate entry without an unique row label. This option is demonstrated in Example 3.
checkDate = boolean (default=N)
Write GDX file only if the CSV file is more recent than the GDX file to save resources when running the model containing the
CSV2GDXcall multiple times. This option is demonstrated in Example 5.
Number of columns in the input file. This parameter is required if there is no header row, since
CSV2GDXdetermines the number of columns from the header row. This option is demonstrated in Example 3. Note that thelastColconstant cannot be used for thecolCountoption.
decimalSep = [Period, Comma] (default=Period)
Specify a decimal separator. The decimal is normally a period, but this parameter allows a comma as the decimal separator, too. Special values recognized are
Eps,NAresp.N/A,Inf,True,False,None,NullandUndef(case insensitive). A string that is not recognized as a valid number will be stored asUndef. This option is demonstrated in Example 2 and Example 6 (focusing on reading special values) for instance.
fieldSep = [Comma, SemiColon, Tab] (default=Comma)
Specify a field separator. Fields are normally separated by a comma, but this parameter allows some additional choices. Using tabs as delimiter should be avoided, since text editors act different on handling them. For instance, one must specify tabs in the GAMS IDE explicitly using %system.tab%:
$onEcho > tabSeparated.csv USA%system.tab%100 GER%system.tab%70 $offEcho $call csv2gdx tabSeparated.csv id=x fieldSep=tab index=1 colCount=2 value=lastColThis option is demonstrated in Example 2 and Example 3 for instance.
Identifier for the symbol in the GDX file. Additional symbols,
Dim1,Dim2, ... for the domain sets of the symbol id will be added automatically to the GDX file. ExecutingCSV2GDXwithout specifying an identifier will fail.
Identify columns to get UELs from. The columns are represented as a list of integers separated by comma. For example
index=1,2,3,4resp.index=(1,2,3,4); in this case the notation1..4is allowed. Brackets can only be used on Windows systems. Theindexoption is used in all examples.
output = filename (default=<CSVFilename>.gdx)
Optional output filename. If no output file is specified,
CSV2GDXwill use the input filename and change the file extension to .gdx. If no path is specified, the output file will be created in the current directory. This option is demonstrated in Example 2 for instance.
Password for an encrypted input file. Use ENDECRYPT to encrypt a file. This option is demonstrated in Example 7.
storeZero = boolean (default=N)
Indicate if zero values are ignored or written as
EPS; an empty field is always ignored. This option is demonstrated in Example 6.
Specify the column to get explanatory text from when reading a set. For example
text=5. This option is demonstrated in Example 9.
Controls the amount of information written to the log. Higher values will generate more output. Valid range is
0..3. Settrace=0to prevent writing any information to the log. This feature is demonstrated in Example 6.
useHeader = boolean (default=N)
Indicate if the first row is a header row. The fields in the header row of the columns specified within the values option will be used as UELs. A header row is not needed or should be ignored when using the colCount or autoCol option. To skip one existing header row while using
autoCol, enableuseHeader. This option is demonstrated in Example 1 and Example 2 for instance.
Specify the column to get the values from. For example
value=5. This option is demonstrated in Example 2.
valueDim = boolean (default=N)
Indicate if an extra dimension for values is added to the parameter even if there is just one value column. This is ignored, if there is no value column. This feature is demonstrated in Example 2.
Specify the columns to get the values from. When using a list of columns for the values and
useHeaderenabled, each field in the first row of the columns is used as UEL to identify the values in those columns. See also useHeader and autoCol below. If the number of columns is unknown, the symbolic constantlastColcan be useful:values=2..lastCol. This option is demonstrated in Example 1 and Example 5 for instance.
Advances and limitations
Advances
CSV2GDXenables the user to read CSV data where the table statement cannot be used without doing further preprocessing, e.g. in case of semicolon- or tab separated data or comma separated decimals.- In general,
CSV2GDXis a quite performant tool compared to the GAMS internal table statement.
Limitations
- Suppose we want to skip some rows while reading the data. For example, if the CSV file contains some reference information in a specific row which we do not want to be stored in the domain sets or in the parameter. However, skipping rows cannot be done with
CSV2GDX. - There might be CSV files with no header and varying, unknown length of rows. Since
CSV2GDXdetermines the number of columns based on the header row or by setting the colCount option in advance,CSV2GDXmight return incorrect results or the execution is aborted. - Reading several parameters from a CSV file cannot be done directly within the
CSV2GDXcall. The data must be split later on as demonstrated in Example 4. CSV2GDXcannot read CSV files containing line breaks within a (quoted) field. You will either get an error message - "Quoted field not terminated with closing quote" - or the result might not be correct for unquoted fields, because the field content will be cut by the line break.
Getting Started
We introduce the basic functionalities of CSV2GDX on some simple examples. Note that many CSV files can be read inside GAMS directly using a table statement, but a number of features available in CSV2GDX enable the user to read a CSV file where the table statement cannot be used, e.g. reading files with semicolon separated data or if the decimals are separated by comma instead of a period.
Example 1 - Reading CSV Files with CSV2GDX
The first example of this collection demonstrates the key commands of CSV2GDX. For instance, consider the table statement of the model [trnsport] from the GAMS Model Library:
Table d(i,j) 'distance in thousands of miles'
new-york chicago topeka
seattle 2.5 1.7 1.8
san-diego 2.5 1.8 1.4;
The data can be stored in distance.csv like this:
,new-york,chicago,topeka seattle,2.5,1.7,1.8 san-diego,2.5,1.8,1.4
First of all, CSV2GDX is called now, to generate distance.gdx by processing the input file distance.csv:
csv2gdx distance.csv id=d index=1 values=2..lastCol useHeader=y
CSV2GDX generates one single parameter d and two domain sets from the input file. The name of the parameter in the GDX file must be declared within the id option, while the domain sets for this parameter will be labeled with Dim1 and Dim2 automatically. Column number one is specified as the first domain set within the index option. The values option is used to specify the column numbers 2,3,4 containing the data values. By enabling the useHeader option, the fields of the first row of the columns specified within the values option will be handled as the second domain set. If the number of columns is unknown in advance, one can use the lastCol constant in the values or index option.



However, to complete the declaration of the sets and parameter for the model trnsport, one must load the data from distance.gdx:
Set
i 'canning plants'
j 'markets';
$gdxIn distance.gdx
$load i = Dim1
$load j = Dim2
Parameter d(i,j) 'distance in thousands of miles';
$load d
$gdxIn
display i, j, d;
This example is also part of the GAMS Data Utilities Library, see model [csv2gdx2] for reference.
Example 2 - Reading Semicolon separated Data
In this example, the distances from the previous example are stored as a list. We want to read the cities and the column containing the miles measurement. Note, that the fields are separated by semicolon and the decimals by comma. As described in Data Exchange with Text Files the CSV file must be preprocessed with the POSIX tools in advance to replace commas by dots and semicolons by commas to read the data directly using a simple table statement.
i;j;miles seattle;new-york;2,5 seattle;chicago;1,7 seattle;topeka;1,8 san-diego;new-york;2,5 san-diego;chicago;1,8 san-diego;topeka;1,4
The data will be stored as distanceOut.gdx by adding the output file option. One can specify the field and decimal separators within the fieldSep and decimalSep option. Domain sets for the parameter to be read are declared by index=1,2.
csv2gdx distance.csv output=distanceOut.gdx id=d fieldSep=semiColon decimalSep=comma index=1,2 useHeader=y value=3
In order to load the data from the GDX file, execute the commands from the previous example. However, note that Dim2 does not contain the UELs from the header row this time, but the unique elements of the second column specified in the index option. The option useHeader is enabled to indicate that there is a header row to be skipped when reading the values. Also note, that the symbol d in the GDX file has exactly two dimensions. It may be useful to add an additional dimension to the parameter dmod, e.g. if different measurement units for the distances may become relevant later on and need to be calculated (kilometer for instance).
This can be done by adding the option valueDim:
csv2gdx distance.csv output=distanceOut.gdx id=d fieldSep=semiColon decimalSep=comma index=1,2 useHeader=y value=3 valueDim=y
The option adds a third dimension to d. Now we want to add the distances in kilometer by calculating the values inside the model:
Set m 'measurement unit' / miles, km /;
Parameter dmod(i,j,m);
$gdxIn distanceOut.gdx
$load dmod = d
$gdxIn
display dmod;
dmod(i,j,'km') = 1.852*dmod(i,j,'miles');
display dmod;
Parameter d (valueDim disabled):
---- 36 PARAMETER d distance in thousands of miles
new-york chicago topeka
seattle 2.500 1.700 1.800
san-diego 2.500 1.800 1.400
Parameter dmod resp. d with valueDim enabled before calculating further measurements:
---- 49 PARAMETER dmod
miles
seattle .new-york 2.500
seattle .chicago 1.700
seattle .topeka 1.800
san-diego.new-york 2.500
san-diego.chicago 1.800
san-diego.topeka 1.400
Parameter dmod with valueDim enabled after calculating the distances in kilometer inside the GAMS model:
---- 52 PARAMETER dmod
miles km
seattle .new-york 2.500 4.630
seattle .chicago 1.700 3.148
seattle .topeka 1.800 3.334
san-diego.new-york 2.500 4.630
san-diego.chicago 1.800 3.334
san-diego.topeka 1.400 2.593
This example is also part of the GAMS Data Utilities Library, see model [csv2gdx3] for reference.
Example 3 - Dealing with missing Labels and Duplicates
Missing Labels
The file EUCData.csv contains the extracted euclidean coordinates of the first nine cities of berlin52.tsp from [TSPLib] (http://comopt.ifi.uni-heidelberg.de/software/TSPLIB95/). You might want to import the data to calculate a complete distance matrix inside GAMS to find an optimal traveling salesman tour for instance.
565.0;575.0 25.0;185.0 345.0;750.0 945.0;685.0 845.0;655.0 880.0;660.0 25.0;230.0 525.0;1000.0 580.0;1175.0
There is no header row, neither a column with labels to serve as domain sets for the coordinates of the cities. However, CSV2GDX automatically generates UELs for columns and rows by adding ascending numbers to an user-defined prefix specified within the autoCol and autoRow option. Also note, because of the missing header, the number of columns in the file must be manually determined and declared within colCount.
csv2gdx EUCData.csv id=coord fieldSep=semiColon autoCol=x autoRow=city colCount=2 values=1,2
The rows will be labeled with city1...city9, the columns with x1 and x2.
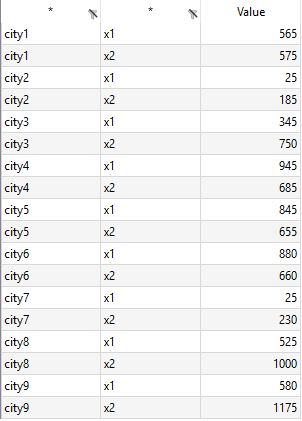
Load the parameter and sets from the GDX file to calculate the complete distance matrix. The set Dim1 contains the UELs city1...city9 for the set i of cities, Dim2 is the set of axes/coordinates i.e. containing the elements x1 and x2 to represent the x-axis and y-axis:
Set
i 'cities'
axes 'x1 and x2 axes';
$gdxIn EUCData.gdx
$load i = Dim1
$load axes = Dim2
Parameter coord(i,axes) 'coordinate of city i';
$load coord
$gdxIn
display coord;
The display statement generates the following output:
---- 43 PARAMETER coord coordinate of city i
x1 x2
city1 565.000 575.000
city2 25.000 185.000
city3 345.000 750.000
city4 945.000 685.000
city5 845.000 655.000
city6 880.000 660.000
city7 25.000 230.000
city8 525.000 1000.000
city9 580.000 1175.000
One could now easily proceed calculating a complete distance matrix:
Alias (i,j);
Parameter c(i,j) 'euclidean distance between city i and j';
c(i,j) = eDist(coord(i,"x1") - coord(j,"x1"),coord(i,"x2") - coord(j,"x2"));
In the previous example, using the autoCol and autoRow option had an additional benefit as we declared the set of the cities on the fly. However, one major advantage/purpose of these options is to prevent error messages or loss of data when reading rows with duplicate keys.
Consider the input file duplicates.csv:
red,red,1 red,red,2 red,green,3 blue,blue,4
Note the duplicate key in the first two rows. By the use of the autoRow parameter in the CSV2GDX call unique labels are added to each row. This way a GAMS program can store all data with duplicate keys and prepare for better error messages.
csv2gdx duplicates.csv id=data index=1,2 value=3 colCount=3 autoRow=row
Ascending numbers will be added to the 'row' prefix specified.
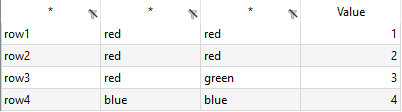
The data can be easily loaded into sets and parameter by executing the following lines:
Set
row 'UELs generated by autoRow'
color 'set of colors';
$gdxIn duplicates.gdx
$load row = Dim1
$load color = Dim2
$loadm color = Dim3
Parameter data(row,color,color);
$load data
$gdxIn
display row, color, data;
Note the usage of the $loadm command to merge all colors into one set of colors. The display statement generates the following output in the listing file:
---- 77 SET row UELs generated by autoRow
row1, row2, row3, row4
---- 77 SET color set of colors
red , blue , green
---- 77 PARAMETER data
red blue green
row1.red 1.000
row2.red 2.000
row3.red 3.000
row4.blue 4.000
The complete example is also part of the GAMS Data Utilities Library, see model [csv2gdx4] for reference.
Example 4 - Reading several Parameters from a single Input File
This example demonstrates how to read the data from a single input file into different parameters. However, this cannot be done directly using the CSV2GDX tool, since CSV2GDX writes to a single parameter (see section limitations). For instance, an energy supplier plans to build new transmission lines from their power plants to some distribution stations. There are different stages for the transmissions lines. The relevant data to be read are the plant and station identifiers, the capacity bounds per transmissions line on a certain stage and the associated cost. The data is all stored in a single file:
plant;station;length;minCap;maxCap;stage;cost p1;s1;100;50;100;1;1200 p1;s2;75;35;65;1;500 p1;s1;100;100;150;2;1800 p2;s1;150;50;100;1;1400 p2;s1;150;100;150;2;2000 p2;s1;150;150;200;3;2350 p2;s2;75;25;50;1;600 p2;s2;75;50;75;2;800 p3;s1;80;40;100;1;1050
Read networkData.csv with CSV2GDX by calling:
csv2gdx networkData.csv id=dataPar useHeader=y fieldSep=semiColon index=1,2,6 values=4,5,7
Note that the stage stored in column six is a domain set, too, while the length of the transmission line in the third column is of no interest. Since CSV2GDX writes to a single parameter, one must split the data later on into minCap, maxCap and cost for instance:
Parameter
dataPar
minCap(plant,station,stage)
maxCap(plant,station,stage)
cost(plant,station,stage);
$gdxIn networkData.gdx
$load plant = Dim1
$load station = Dim2
$load stage = Dim3
$load dataPar
$gdxIn
minCap(plant,station,stage) = dataPar(plant,station,stage,'minCap');
maxCap(plant,station,stage) = dataPar(plant,station,stage,'maxCap');
cost(plant,station,stage) = dataPar(plant,station,stage,'cost');
This example is also part of the GAMS Data Utilities Library, see model [csv2gdx5] for reference.
Example 5 - Reading economic Data from the World Bank Data Catalog
This example demonstrates how to read some real CSV data from the [World Bank Data Catalog] (https://datacatalog.worldbank.org/). Suppose we want to read some time series data, e.g. GDP growth rates. The data is structured as follows (rows shortened for presentation):
"Country Name","Country Code","Indicator Name","Indicator Code","1999","2000","2001","2002","2003","2004","2005","2006","2007","2008","2009","2010","2011","2012","2013","2014","2015","2016","2017","2018","2019","2020", "East Asia and Pacific","EAA","GDP growth, constant 2010 USD","NYGDPMKTPKDZ","","","","","","","","","","","","","","","","","6.503564548","6.327469798","6.449458613","6.181694329","6.065321782","5.964012702",
We are not interested in the "Country Code", "Indicator Name" and "Indicator Code". Since the annual GDP rate per country is unique, the CSV2GDX call is quite easy despite the large number of columns. Note that there are only a few limitations of CSV2GDX, discussed in the section Advances and limitations. Empty fields in the data will always be ignored, causing no trouble at all if the field separators are set correctly.
csv2gdx GDPData.csv id=GDPG index=1 values=5..lastCol useHeader=y checkDate=y
The option checkDate is enabled to save resources if you run the model multiple times, as the GDX file is only written if the CSV file is more recent than the GDX file. To load the sets and parameter from the GDX file, execute the following commands:
Set country, year;
$gdxIn GDPData.gdx
$load country = Dim1
$load year = Dim2
Parameter GDPRate(country,year);
$load GDPRate
$gdxIn
display country, year, GDPRate;
The display statement generates the following output in the listing file. Obviously, double quotes are removed from the fields of the value columns, but also from the index columns:
---- 12 SET country
East Asia and Pacific, Europe and Central Asia, Latin America and the Caribbean, Middle East and North Africa, South Asia, Sub-Saharan Africa, World (WBG members)
Afghanistan , Albania , Algeria , Angola , Argentina , Armenia , Azerbaijan
---- 12 SET year
2015, 2016, 2017, 2018, 2019, 2020
---- 12 PARAMETER GDPR
2015 2016 2017 2018 2019 2020
East Asia and Pacific 6.504 6.327 6.449 6.182 6.065 5.964
Europe and Central Asia 0.963 1.672 3.782 2.901 3.029 2.969
Latin America and the Caribbean -0.562 -1.526 0.902 2.044 2.586 2.701
Note that the listings have been shortened for presentation. However, there is no data for the years 1999-2014.
This example is also part of the GAMS Data Utilities Library, see model [csv2gdx6] for reference.
Additional Examples for extended Use
The examples in this section discuss some special features. Some topics were already mentioned briefly in the previous section like reading compressed and encrypted files or reading the CSV2GDX options from an external file.
Example 6 - Reading special Values
To illustrate how special values are interpreted, consider the following data:
one,two,three,four,five,six red,red,,Undef,'3.3',red red,red,"4.4",5.5,Eps,green "red",'green',7.7e+02,8.8°,-Inf,blue blue,blue,10,0,NA,purple brown,blue,true,false,N/A,green black,red,None,Null,"True",blue
Calling CSV2GDX to read the data and write to GDX:
csv2gdx data.csv id=A index=1,2,6 values=3..5 useHeader=y storeZero=y trace=3
The GAMS log reports three occurrences of undefined values. Note that the amount of information written to the log was increased by setting the option trace=3.
--- call csv2gdx specialValues.csv id=A index=1,2,6 values=3..5 useHeader=y storeZero=y trace=3 CSV2GDX 25.2.0 r67638 ALFA Released 15Aug18 WEI x86 64bit/MS Windows Header enabled, number of columns = 6 1: one 2: two 3: three 4: four 5: five 6: six 2: |red|, |red|, ||, |Undef|, |'3.3'|, |red| 3: |red|, |red|, |4.4|, |5.5|, |Eps|, |green| 4: |red|, |'green'|, |7.7e+02|, |8.8°|, |-Inf|, |blue| 5: |blue|, |blue|, |10|, |0|, |NA|, |purple| Undef Count = 3, No errors, CSV2GDX time = 157ms
As mentioned in decimalSep, CSV2GDX fails to recognize the number 8.8 from the string 8.8° because of the unknown special character, while 7.7e+02 is interpreted as a number of course. Watch out if there are quotes in the values or index columns. The number 4.4 enclosed by double quotes is interpreted as a number, while '3.3' is not (as you can see in the log, the double quotes are eliminated, while the single quotes remain). In the first column, the double quotes enclosing the string red are removed, while the single quotes in the second column enclosing the string green are not removed. The zero value is stored as EPS by setting storeZero=y. Note that no error was reported, even though some of the values stored as Undef may cause some trouble in your model later on (use $onUndf to enable loading parameters with undefined values).
The booleans true and false in the second last row are represented by the numericals 1 resp. 0 within GAMS. The special values None and Null will be converted to 0. Since storeZore is enabled in this example, the value displayed for false, None and Null is EPS.
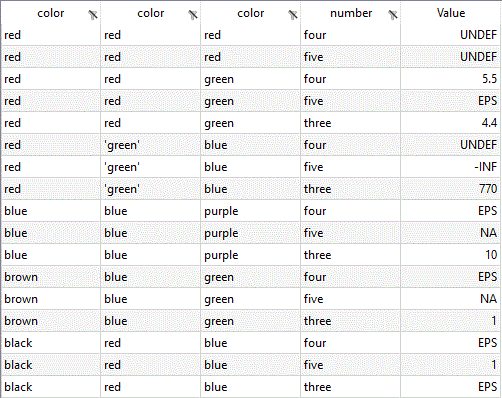
Suppose we want to declare the parameter A as: A(color,color,color,number). We can proceed as follows:
Set color, number;
$gdxIn data.gdx
$load color = Dim1
$loadm color = Dim2
$loadm color = Dim3
$load number = Dim4
Parameter A(color,color,color,number);
$onUndf
$load A
$offUndf
$gdxIn
display A;
Loading undefined values is enabled by adding $onUndf. This example is also part of the GAMS Data Utilities Library, see model [csv2gdx7] for reference.
Example 7 - Reading a compressed encrypted Input File
Reading a compressed input file is supported by CSV2GDX. The gzip program in the gbin sub-directory or ENDECRYPT must be used for compression. Call gzip to compress the CSV file by running the following command:
gzip compressMe.csv -c > compressedFile.csv.gz
Gzip writes to standard output by appending -c to keep the original file unchanged. The output is then redirected to compressedFile.csv.gz. To read the compressed file, call CSV2GDX with the same options as for processing the uncompressed file.
csv2gdx compressedFile.csv.gz output=unCompressedGzipFile.gdx id=d index=1 useHeader=y values=2..lastCol
The data in this example is taken from Example 1.
While the main purpose of Endecrypt is about encrypting and decrypting files, it also compresses the file. If you want to compress a file with Endecrypt, do not specify an password file:
cat compressMe.csv | endecrypt -W compressedFile.csv
The option -W encrypts standard input and writes to compressedFile.csv. Although there will be no encryption because of the missing password file, one must set the option -W. You can read the compressed file with CSV2GDX:
csv2gdx compressedFile.csv output=unCompressedEndycryptFile.gdx id=d index=1 useHeader=y values=2..lastCol
Note that there is no further file extension added.
By adding a password file (containing the password in the first line), Endecrypt encrypts and compresses the input file:
cat compressMe.csv | endecrypt -W compressedEncryptedFile.csv passwordFile.txt
The password file will be deleted. Execute the following command to read the compressed and encrypted file with CSV2GDX:
csv2gdx compressedEncryptedFile.csv output=unCompressedDecryptedFile.gdx password=Anton id=d index=1 useHeader=y values=2..lastCol
The password option is added. You must set the password directly within the option, in this case "Anton", not the password file. Note that CSV2GDX does not support .gz, .7z etc. compressed files!
This example is also part of the GAMS Data Utilities Library, see model [csv2gdx8] for reference.
Example 8 - Reading Options from an external File
This example demonstrates how to read the options from an external text file as already mentioned in section Filename. The file distance.csv from the Getting Started Example 1 will be processed with CSV2GDX while reading the options from an external text file named howToRead.txt.
csv2gdx distance.csv @howToRead.txt
Swapping the order of the CSV filename and the instructions filename inside the call statement will cause an error. Note the leading @ (at sign) on the instructions file, containing the following options:
* These lines are interpreted as a comment * This file specifies the options for reading distance.csv using CSV2GDX id = d fieldSep = semiColon decimalSep = comma index = 1 useHeader = y values = 2..lastCol
This example is also part of the GAMS Data Utilities Library, see model [csv2gdx9] for reference.
Example 9 - Reading Set Elements with explanatory Text
In this example, we will demonstrate how to read explanatory text of set elements using the CSV2GDX option text.
Consider the input file data.csv:
a1,b1,explanatory text of a1.b1,10 a1,b2,explanatory text of a1.b2,20 a2,b1,explanatory text of a2.b1,30 a2,b2,explanatory text of a2.b2,40
The set elements are stored in the first and second column, the explanatory text is stored in the third column and there is a fourth column containing some values. Suppose we want to read a two-dimensional set with explanatory text. By default, CSV2GDX does not read explanatory text, i.e. by running the following command:
csv2gdx data.csv id=abOnlyUELs index=1,2 colCount=4
CSV2GDX creates a GDX file containing the two-dimensional set abOnlyUELs without explanatory text (needless to say, we did not specify a column to get the explanatory text from). By specifying the third column within the index option, i.e. index=1..3, the result will be a three-dimensional set (without explanatory text, too). Using the value option is not suitable, as the data type will be a parameter instead of a set (in addition, CSV2GDX expects numeric data, potentially leading to undefined values). We can read the explanatory text easily by specifying column three within the text option:
csv2gdx data.csv id=abWithExpText index=1,2 text=3 colCount=4
The figure shows the set abOnlyUELs on the left without explanatory text and the set abWithExpText on the right:

Note that the text and value(s) options cannot be used at the same time (instead, use multiple CSV2GDX calls in scenarios when you wish to read set elements with explanatory text and parameters from a single data set).