Table of Contents
- Introduction
- Iteration Output
- CONOPT Termination Messages
- Function Evaluation Errors
- The CONOPT Options File
- Hints on Good Model Formulation
- NLP and DNLP Models
- APPENDIX A: Algorithmic Information
- Overview of CONOPT
- The CONOPT Algorithm
- Iteration 0: The Initial Point
- Iteration 1: Preprocessing
- Iteration 2: Scaling
- Finding a Feasible Solution: Phase 0
- Finding a Feasible Solution: Phase 1 and 2
- Linear and Nonlinear Mode: Phase 1 to 4
- Linear Mode: The SLP Procedure
- Linear Mode: The Steepest Edge Procedure
- Nonlinear Mode: The SQP Procedure
- How to Select Non-default Options
- Miscellaneous Topics
- APPENDIX B - Options
- APPENDIX C: References
Introduction
This documentation is for CONOPT3. We will refer to CONOPT3 as CONOPT in the following. Note that there is also the improved version CONOPT4.
Nonlinear models created with GAMS must be solved with a nonlinear programming (NLP) algorithm. Currently, there is a large number of different solvers available and the number is growing.
The most important distinction between the solvers is whether they attempt to find a local or a global solution. Solvers that attempt to find a global solution (so called Global Solvers) can usually not solve very large models. As a contrast most Local Solvers can work with much larger models, and models with over 10,000 variables and constraints are not unusual. If the model has the right mathematical properties, e.g. is convex, then Local Solvers will find a global optimum. Unfortunately, the mathematical machinery for testing whether a general NLP model is convex or not has not yet been developed (and is expected to be in the class or hard problems).
It is almost impossible to predict how difficult it is to solve a particular model with a particular algorithm, especially for NLP models, so GAMS cannot select the best algorithm for you automatically. When GAMS is installed you must select one of the nonlinear programming algorithms as the default solver for NLP models. If you want to switch between algorithms for a particular model you may add the statement Option NLP = <solvername>, in your GAMS source file before the Solve statement, you may add NLP = <solvername> on the GAMS command line or by rerunning the gamsinst program.
The only reliable way to find which solver to use for a particular class of models is so far to experiment. However, there are a few rules of thumb:
CONOPT is well suited for models with very nonlinear constraints. If you experience that a solver has problems maintaining feasibility during the optimization you should try CONOPT. On the other hand, if you have a model with few nonlinearities outside the objective function then other solvers could be the best solver.
CONOPT has a fast method for finding a first feasible solution that is particularly well suited for models with few degrees of freedom. If you have a model with roughly the same number of constraints as variable you should try CONOPT. CONOPT can also be used to solve square systems of equations without an objective function corresponding to the GAMS model class CNS - Constrained Nonlinear System.
CONOPT can use second derivatives. If the number of variables is much larger than the number of constraints CONOPT will use second derivatives and overall progress can be considerably faster than for MINOS or SNOPT. IPOPT and KNITRO will also use second derivatives, but the method is very different and it is not possible to predict which solver will be better.
CONOPT has a preprocessing step in which recursive equations and variables are solved and removed from the model. If you have a model where many equations can be solved one by one then CONOPT will take advantage of this property. Similarly, intermediate variables only used to define objective terms are eliminated from the model and the constraints are moved into the objective function.
CONOPT has many built-in tests and messages, and many models that can and should be improved by the modeler are rejected with a constructive message. CONOPT is therefore also a helpful debugging tool during model development. The best solver for the final, debugged model may or may not be CONOPT.
CONOPT has been designed for large and sparse models. This means that both the number of variables and equations can be large. Indeed, NLP models with over 100,000 equations and variables have been solved successfully, and CNS models with over 1,000,000 equations and variables have also been solved. The components used to build CONOPT have been selected under the assumptions that the model is sparse, i.e. that most functions only depend on a small number of variables. CONOPT can also be used for denser models, but the performance will suffer significantly.
CONOPT is designed for models with smooth functions, but it can also be applied to models that do not have differentiable functions, in GAMS called DNLP models. However, CONOPT will use the same algorithm used for a real NLP model and it will search for a point that satisfies standard first-order optimality conditions without taking into account that parts of the model could be non-smooth or non-differentiable. The lack of smoothness may confuse the algorithm in CONOPT causing slow convergence, and a point that satisfies standard first-order optimality conditions may not even exist. There are therefore no guaranties whatsoever for this class of models. If CONOPT terminates with a locally optimal solution then the solution will indeed be locally optimal. However, you will sometimes get termination messages like "Convergence too slow" or "No change in objective although the reduced gradient is greater than the tolerance" that indicate unsuccessful termination. The final point may or may not be locally optimal. If possible, you should try to reformulate a DNLP model to an equivalent or approximately equivalent form as described in section NLP and DNLP Models .
Most modelers should not be concerned with algorithmic details such as choice of algorithmic sub-components or tolerances. CONOPT has considerable build-in logic that selects a solution approach that seems to be best suited for the type of model at hand, and the approach is adjusted dynamically as information about the behavior of the model is collected and updated. The description of the CONOPT algorithm has therefore been moved to an appendix (Appendix A) and most modelers can skip it. However, if you are solving very large or complex models or if you are experiencing solution difficulties you may benefit from using non-standard tolerances or options, in which case you will need some understanding of what CONOPT is doing to your model. Some guidelines for selecting options can be found at the end of Appendix A and a list of all options and tolerances is shown in Appendix B.
The main text of this User's Guide will give a short overview over the iteration output you will see on the screen (section Iteration Output), and explain the termination messages (section CONOPT Termination Messages). We will then discuss function evaluation errors (section Function Evaluation Errors), the use of options (section The CONOPT Options File), and give a CONOPT perspective on good model formulation including topics such as initial values and bounds, simplification of expressions, and scaling (section Hints on Good Model Formulation). Finally, we will discuss the difference between NLP and DNLP models (section NLP and DNLP Models).
Iteration Output
On most machines you will by default get a logline on your screen or terminal at regular intervals. The iteration log may look something like this:
CONOPT 3 Jul 4, 2012 23.9.4 WEX 35892.35906 WEI x86_64/MS Windows
C O N O P T 3 version 3.15G
Copyright (C) ARKI Consulting and Development A/S
Bagsvaerdvej 246 A
DK-2880 Bagsvaerd, Denmark
Iter Phase Ninf Infeasibility RGmax NSB Step InItr MX OK
0 0 1.6354151782E+01 (Input point)
Pre-triangular equations: 2
Post-triangular equations: 1
1 0 1.5354151782E+01 (After pre-processing)
2 0 3.0983571843E+00 (After scaling)
10 0 12 3.0814290456E+00 0.0E+00 T T
20 0 12 3.0814290456E+00 0.0E+00 T T
30 0 13 3.0814290456E+00 0.0E+00 F F
40 0 18 2.3738740159E+00 2.3E-02 T T
50 0 23 2.1776589484E+00 0.0E+00 F F
Iter Phase Ninf Infeasibility RGmax NSB Step InItr MX OK
60 0 33 2.1776589484E+00 0.0E+00 T T
70 0 43 2.1776589484E+00 0.0E+00 F F
80 0 53 2.1776589484E+00 0.0E+00 F F
90 0 63 2.1776589484E+00 0.0E+00 F F
100 0 73 2.1776589484E+00 0.0E+00 F F
110 0 83 2.1776589484E+00 0.0E+00 F F
120 0 93 2.1776589484E+00 0.0E+00 F F
130 0 103 2.1776589484E+00 0.0E+00 F F
140 0 113 2.1776589484E+00 0.0E+00 T T
150 0 119 8.7534351971E-01 0.0E+00 F F
Iter Phase Ninf Infeasibility RGmax NSB Step InItr MX OK
160 0 124 9.5022881759E-01 0.0E+00 F F
170 0 134 9.5022881759E-01 0.0E+00 F F
180 0 144 9.5022881759E-01 0.0E+00 F F
190 0 154 9.5022881759E-01 0.0E+00 F F
201 1 160 9.4182618946E-01 4.3E+01 134 2.4E-06 T T
206 1 130 8.2388503304E-01 9.5E+01 138 1.0E+00 13 T T
211 1 50 1.0242911941E-01 6.9E+00 84 7.2E-01 24 T T
216 1 16 2.6057507770E-02 1.3E+00 52 6.1E-01 17 T T
221 1 5 7.2858773666E-04 6.1E-03 38 6.0E-01 7 F F
** Feasible solution. Value of objective = 1.00525015566
Iter Phase Ninf Objective RGmax NSB Step InItr MX OK
226 3 1.0092586645E+00 4.4E-04 38 1.0E+00 3 T T
231 3 1.0121749760E+00 1.4E+00 24 4.8E-01 9 T T
236 3 1.0128148550E+00 4.8E-06 13 5.8E-02 12 F T
241 3 1.0128161551E+00 2.5E-06 12 9.1E+03 F T
246 4 1.0128171043E+00 1.2E-07 13 1.0E+00 3 F T
247 4 1.0128171043E+00 5.7E-08 13
** Optimal solution. Reduced gradient less than tolerance.
The first few lines identify the version of CONOPT you use.
The first iterations have a special interpretation: iteration 0 represents the initial point exactly as received from GAMS, iteration 1 represent the point that is the result of CONOPT's pre-processing, and iteration 2 represents the same point after scaling (even if scaling is turned off).
The remaining iterations are characterized by the value of "Phase" in column 2. The model is infeasible during Phase 0, 1, and 2 and the Sum of Infeasibilities in column 4 (labeled "Infeasibility") is being minimized; the model is feasible during Phase 3 and 4 and the actual objective function, also shown in column 4 (now labeled "Objective"), is minimized or maximized. Phase 0 iterations are Newton-like iterations. They are very cheap so you should not be concerned if there are many of these Phase 0 iterations. During Phase 1 and 3 the model behaves almost linearly and CONOPT applies special linear iterations that take advantage of the linearity. These iterations are sometimes augmented with some inner "Sequential Linear Programming" (SLP) iterations, indicated by a number of inner SLP iterations in the "InItr" column. During Phase 2 and 4 the model behaves more nonlinear and most aspects of the iterations are therefore changed: the line search is more elaborate, and CONOPT needs second order information to improve the convergence. For small and simple models CONOPT will approximate second order information as a byproduct of the line searches. For larger and more complex models CONOPT will use some inner "Sequential Quadratic Programming" (SQP) iterations based on exact second derivatives. These SQP iterations are identified by the number of inner SQP iterations in the "InItr" column.
The column "NSB" for Number of SuperBasics defines the degree of freedom or the dimension of the current search space, and "rgmax" measures the largest reduced gradient among the non-optimal variables. Rgmax should eventually converge towards zero, but convergence is not expected to be monotone. The last two columns labeled "MX" and "OK" gives information about the line search: OK = T means that the line search was well-behaved, and OK = F means that the line search was terminated before an optimal step length was found because it was not possible to find a feasible solution for large step lengths. MX = T means that the line search was terminated by a variable reaching a bound (always combined with OK = T), and MX = F means that the step length was determined by nonlinearities. If OK = T then the step length was optimal; if OK = F then the constraints were too nonlinear to allow CONOPT to make a full optimal step.
CONOPT Termination Messages
CONOPT may terminate in a number of ways. This section will show most of the termination messages and explain their meaning. It will also show the Model Status returned to GAMS in <model>.modelStat, where <model> represents the name of the GAMS model. The Solver Status returned in <model>.solveStat will be given if it is different from 1 (Normal Completion). We will in all cases first show the message from CONOPT followed by a short explanation. The first 4 messages are used for optimal solutions and CONOPT will return modelStat = 2 (Locally Optimal), except as noted below:
** Optimal solution. There are no superbasic variables.
The solution is a locally optimal corner solution. The solution is determined by constraints only, and it is usually very accurate. In some cases CONOPT can determine that the solution is globally optimal and it will return modelStat = 1 (Optimal).
** Optimal solution. Reduced gradient less than tolerance.
The solution is a locally optimal interior solution. The largest component of the reduced gradient is less than the tolerance rtredg with default value 1.e-7. The value of the objective function is very accurate while the values of the variables are less accurate due to a flat objective function in the interior of the feasible area.
** Optimal solution. The error on the optimal objective function
value estimated from the reduced gradient and the estimated
Hessian is less than the minimal tolerance on the objective.
The solution is a locally optimal interior solution. The largest component of the reduced gradient is larger than the tolerance rtredg. However, when the reduced gradient is scaled with information from the estimated Hessian of the reduced objective function the solution seems optimal. For this to happen the objective must be large or the reduced objective must have large second derivatives so it is advisable to scale the model. See the sections on "Scaling" and "Using the Scale Option in GAMS" for details on how to scale a model.
** Optimal solution. Convergence too slow. The change in
objective has been less than xx.xx for xx consecutive
iterations.
CONOPT stops with a solution that seems optimal. The solution process is stopped because of slow progress. The largest component of the reduced gradient is greater than the optimality tolerance rtredg, but less than rtredg multiplied by the largest Jacobian element divided by 100. The model must have large derivatives so it is advisable to scale it.
The four messages above all exist in versions where "Optimal" is replaced by "Infeasible" and modelStat will be 5 (Locally Infeasible) or 4 (Infeasible). The infeasible messages indicate that a Sum of Infeasibility objective function is locally minimal, but positive. If the model is convex it does not have a feasible solution; if the model is non-convex it may have a feasible solution in a different region. See the section on "Initial Values" for hints on what to do.
** Feasible solution. Convergence too slow. The change in
objective has been less than xx.xx for xx consecutive
iterations.
** Feasible solution. The tolerances are minimal and
there is no change in objective although the reduced
gradient is greater than the tolerance.
The two messages above tell that CONOPT stops with a feasible solution. In the first case the solution process is very slow and in the second there is no progress at all. However, the optimality criteria have not been satisfied. These messages are accompanied by modelStat = 7 (Feasible Solution) and solveStat = 4 (Terminated by Solver). The problem can be caused by discontinuities if the model is of type DNLP; in this case you should consider alternative, smooth formulations as discussed in section NLP and DNLP Models . The problem can also be caused by a poorly scaled model. See section Scaling for hints on model scaling. Finally, it can be caused by stalling as described in section Stalling in Appendix A. The two messages also exist in a version where "Feasible" is replaced by "Infeasible". modelStat is in this case 6 (Intermediate Infeasible) and solveStat is still 4 (Terminated by Solver); these versions tell that CONOPT cannot make progress towards feasibility, but the Sum of Infeasibility objective function does not have a well defined local minimum.
<var>: The variable has reached infinity
** Unbounded solution. A variable has reached 'infinity'.
Largest legal value (Rtmaxv) is xx.xx
CONOPT considers a solution to be unbounded if a variable exceeds the indicated value of rtmaxv (default 1.e10) and it returns with modelStat = 3 (Unbounded). The check for unboundedness is done at every iteration which means that CONOPT will stop if an intermediate solution has a variable that is very large, even if none of the variables in the optimal solution have large values. Check whether the solution appears unbounded or the problem is caused by the scaling of the unbounded variable "<var>" mentioned in the first line of the message. If the model seems correct you are advised to scale it. There is also a lazy solution: you can increase the largest legal value, rtmaxv, as mentioned in the section on options. However, you will pay through reduced reliability or increased solution times. Unlike LP models, where an unbounded model is recognized by an unbounded ray and the iterations are stopped far from "infinity", CONOPT will actually have to make a line search and move to a region with large values of the variables. This may lead to bad scaling and to many different kinds of tolerance and roundoff problems, including problems of determining whether a solution is feasible or not.
The message above exists in a version where "Unbounded" is replaced by "Infeasible" and modelStat is 5 (Locally Infeasible). You may also see a message like
<var>: Free variable becomes too large
** Infeasible solution. A free variable exceeds the allowable
range. Current value is 1.02E+10 and current upper bound
(Rtmaxv) is 1.00E+10
These two messages indicate that some variables become very large before a feasible solution has been found. You should again check whether the problem is caused by the scaling of the unbounded variable "<var>" mentioned in the first line of the message. If the model seems correct you should scale it.
** The time limit has been reached.
The time or resource limit defined in GAMS, either by default (usually 1000 seconds) or by Option ResLim = xx; or <model>.ResLim = xx; statements, has been reached. CONOPT will return with solveStat = 3 (Resource Interrupt) and modelStat either 6 (Locally Infeasible) or 7 (Feasible Solution).
** The iteration limit has been reached.
The iteration limit defined in GAMS, either by default (usually 2000000000 iterations) or by Option IterLim = xx; or <model>.IterLim = xx; statements, has been reached. CONOPT will return with solveStat = 2 (Iteration Interrupt) and modelStat either 6 (Locally Infeasible) or 7 (Feasible Solution).
** Domain errors in nonlinear functions.
Check bounds on variables.
The number of function evaluation errors has reached the limit defined in GAMS by Option DomLim = xx; or <model>.DomLim = xx; statements or the default limit of 0 function evaluation errors. CONOPT will return with solveStat = 5 (Evaluation Error Limit) and modelStat either 6 (Locally Infeasible) or 7 (Feasible Solution). See more details in section Function Evaluation Errors .
** An initial derivative is too large (larger than Rtmaxj= xx.xx)
Scale the variables and/or equations or add bounds.
<var> appearing in
<equ>: Initial Jacobian element too large = xx.xx
and
** A derivative is too large (larger than Rtmaxj= xx.xx).
Scale the variables and/or equations or add bounds.
<var> appearing in
<equ>: Jacobian element too large = xx.xx
These two messages appear if a derivative or Jacobian element is very large, either in the initial point or in a later intermediate point. The relevant variable and equation pair(s) will show you where to look. A large derivative means that the function changes very rapidly even after a very small change in the variable and it will most likely create numerical problems for many parts of the optimization algorithm. Instead of attempting to solve a model that most likely will fail, CONOPT will stop and you are advised to adjust the model if at all possible.
If the offending derivative is associated with a Log(x) or 1/x term you may try to increase the lower bound on x. If the offending derivative is associated with an Exp(x) term you must decrease the upper bound on x. You may also try to scale the model, either manually or using the variable.Scale and/or equation.Scale option in GAMS as described in section Scaling There is also in this case a lazy solution: increase the limit on Jacobian elements, rtmaxj; however, you will pay through reduced reliability or longer solution times.
In addition to the messages shown above you may see messages like
** An equation in the pre-triangular part of the model cannot be
solved because the critical variable is at a bound.
** An equation in the pre-triangular part of the model cannot be
solved because of too small pivot.
or
** An equation is inconsistent with other equations in the
pre-triangular part of the model.
These messages containing the word "Pre-triangular" are all related to infeasibilities identified by CONOPT's pre-processing stage and they are explained in detail in section Iteration 1: Preprocessing in Appendix A.
Usually, CONOPT will be able to estimate the amount of memory needed for the model based on statistics provided by GAMS. However, in some cases with unusual models, e.g. very dense models or very large models, the estimate will be too small and you must request more memory yourself using a statement like <model>.WorkFactor = x.x; or <model>.WorkSpace = xx; in GAMS or by adding WorkFactor=xx to the command line call of GAMS. The message you will see is similar to the following:
** FATAL ERROR ** Insufficient memory to continue the
optimization.
You must request more memory.
Current CONOPT space = 0.29 Mbytes
Estimated CONOPT space = 0.64 Mbytes
Minimum CONOPT space = 0.33 Mbytes
CONOPT time Total 0.109 seconds
of which: Function evaluations 0.000 = 0.0%
1st derivative evaluations 0.000 = 0.0%
The text after "Insufficient memory to" may be different; it says something about where CONOPT ran out of memory. If the memory problem appears during model setup the message will be accompanied by solveStat = 13 (System Failure) and modelStat = 13 (Error No Solution) and CONOPT will not return any values. If the memory problem appears later during the optimization solveStat will be 11 (Internal Solver Failure) and modelStat will be either 6 (Intermediate Infeasible) or 7 (Feasible Solution) and CONOPT will return primal solution values. The marginals of both equations and variables will be zero or EPS.
It is recommended that you use the WorkFactor option if you must change the amount of memory. The same number will usually work for a whole family of models. If you prefer to use WorkSpace, the GAMS WorkSpace option corresponds to the amount of memory, measured in Mbytes.
A new termination message has been added from version 3.16C:
** Feasible solution. The solution process has been terminated
because intermediate results have become NaN (Not A Number).
and similar with Infeasible. To prevent non-sensible results and/or infinite loops in special degenerate cases CONOPT has added checks for internal intermediate results being NaN (Not A Number) or very large. If this happens CONOPT will try to change some tolerances and try to continue the optimization. If this attempt fails CONOPT will stop and return the message above. The solver status will return 4 "Terminated by Solver" and model status 6 or 7, "Intermediate Infeasible" or "Intermediate Feasible." Section Overflow and NaN (Not A Number) in Appendix A has more details on the sources of NaN and the actions that can be taken by the user and by CONOPT.
Function Evaluation Errors
Many of the nonlinear functions available with GAMS are not defined for all values of their arguments. Log is not defined for negative arguments, Exp overflows for large arguments, and division by zero is illegal. To avoid evaluating functions outside their domain of definition you should add reasonable variable bounds. CONOPT will in return guarantee that the nonlinear functions never are evaluated with variables outside their bounds.
In some cases bounds are not sufficient, e.g. in the expression Log( Sum(i, x(i) ) ): in some models each individual x should be allowed to become zero, but the Sum should not. In this case you should introduce an intermediate variable and an extra equation, e.g. xSumDef .. xSum =E= sum(i,x(i)); add a lower bound on xSum; and use xSum as the argument to the Log function. See section Simple Expressions for additional comments on this topic.
Whenever a nonlinear function is called outside its domain of definition, GAMS' function evaluator will intercept the function evaluation error and prevent the system to crash. GAMS will replace the undefined result by some appropriate real number, and it will make sure the error is reported to the modeler as part of the standard solution output in the GAMS listing file. GAMS will also report the error to CONOPT, so CONOPT can try to correct the problem by backtracking to a safe point. Finally, CONOPT will be instructed to stop after DomLim errors.
During Phase 0, 1, and 3 CONOPT will often use large steps as the initial step in a line search and functions will very likely be called with some of the variables at their lower or upper bound. You are therefore likely to get a division-by-zero error if your model contains a division by x and x has a lower bound of zero. And you are likely to get an exponentiation overflow error if your model contains Exp(x) and x has no upper bound. However, CONOPT will usually not get trapped in a point outside the domain of definition for the model. When GAMS' function evaluator reports that a point is "bad", CONOPT will decrease the step length, and it will for most models be able to recover and continue to an optimal solution. It is therefore safe to use a large value for DomLim instead of GAMS default value of 0.
CONOPT may get stuck in some cases, for example because there is no previous point to backtrack to, because "bad" points are very close to "reasonable" feasible points, or because the derivatives are not defined in a feasible point. The more common messages are:
** Fatal Error ** Function error in initial point in Phase 0
procedure.
** Fatal Error ** Function error after small step in Phase 0
procedure.
** Fatal Error ** Function error very close to a feasible point.
** Fatal Error ** Function error while reducing tolerances.
** Fatal Error ** Function error in Pre-triangular equations.
** Fatal Error ** Function error after Preprocessing.
** Fatal Error ** Function error in Post-triangular equation.
In the first four cases you must either add better bounds or define better initial values. If the problem is related to a pre- or post-triangular equation as shown by the last three messages then you can turn part of the pre-processing off as described in section Iteration 1: Preprocessing . in Appendix A. However, this may make the model harder to solve, so it is usually better to add bounds and/or initial values.
The CONOPT Options File
CONOPT has been designed to be self-tuning. Most tolerances are dynamic. As an example: The feasibility of a constraint is always judged relative to the dual variable on the constraint and relative to the expected change in objective in the coming iteration. If the dual variable is large then the constraint must be satisfied with a small tolerance, and if the dual variable is small then the tolerance is larger. When the expected change in objective in the first iterations is large then the feasibility tolerances are also large. And when we approach the optimum and the expected change in objective becomes smaller then the feasibility tolerances become smaller.
Because of the self-tuning nature of CONOPT you should in most cases be well off with default tolerances. If you do need to change some tolerances, possibly following the advice in Appendix A, it can be done in the CONOPT Options file. The name of the CONOPT Options file is on most systems "conopt.opt". You must tell the solver that you want to use an options file with the statement <model>.OptFile = 1 in your GAMS source file before the Solve statement or with OptFile = 1 on the command line.
The format of the CONOPT Options file consists in its simplest form of a number of lines like these:
rtmaxv = 1.e12 lfnsup = 500
The value must be written using legal GAMS format, i.e. a real number may contain an optional E exponent, but a number may not contain blanks. The value must have the same type as the option, i.e. real options must be assigned real values, integer options must be assigned integer values, and logical options must be assigned logical values. The logical value representing true are true, t, yes, or 1, and the logical values representing false are false, f, no, or 0.
In previous versions of CONOPT you could add "SET" in front of the option assignment. This is no longer supported. You can still replace the equal sign with := and you can add end of line comments after a # or ! character. Lines starting with * in column 1 are treated as comment lines.
Hints on Good Model Formulation
This section will contain some comments on how to formulate a nonlinear model so it becomes easier to solve with CONOPT. Most of the recommendations will be useful for any nonlinear solver, but not all. We will try to mention when a recommendation is CONOPT specific.
Initial Values
Good initial values are important for many reasons. Initial values that satisfy or closely satisfy many of the constraints reduces the work involved in finding a first feasible solution. Initial values that in addition are close to the optimal ones also reduce the distance to the final point and therefore indirectly the computational effort. The progress of the optimization algorithm is based on good directional information and therefore on good derivatives. The derivatives in a nonlinear model depend on the current point, and the initial point in which the initial derivatives are computed is therefore again important. Finally, non-convex models may have multiple solutions, but the modeler is looking for one in a particular part of the search space; an initial point in the right neighborhood is more likely to return the desired solution.
The initial values used by CONOPT are all coming from GAMS. The initial values used by GAMS are by default the value zero projected on the bounds. I.e. if a variable is free or has a lower bound of zero, then its default initial value is zero. Unfortunately, zero is in many cases a bad initial value for a nonlinear variable. An initial value of zero is especially bad if the variable appears in a product term since the initial derivative becomes zero, and it appears as if the function does not depend on the variable. CONOPT will warn you and ask you to supply better initial values if the number of derivatives equal to zero is larger than 20 percent.
If a variable has a small positive lower bound, for example because it appears as an argument to the Log function or as a denominator, then the default initial value is this small lower bound and it is also bad since this point will have very large first and second derivatives.
You should therefore supply as many sensible initial values as possible by making assignment to the level value, var.L, in GAMS. An easy possibility is to initialize all variables to 1, or to the scale factor if you use GAMS' scaling option. A better possibility is to select reasonable values for some variables that from the context are known to be important, and then use some of the equations of the model to derive values for other variables. A model may contain the following equation:
pmDef(it) .. pm(it) =e= pwm(it)*er*(1 + tm(it)) ;
where pm, pwm, and er are variables and tm is a parameter. The following assignment statements use the equation to derive consistent initial values for PM from sensible initial values for pwm and er:
er.l = 1; pwm.l(it) = 1; pm.l(it) = pwm.l(it)*er.l*(1 + tm(it)) ;
With these assignments equation pmDef will be feasible in the initial point, and since CONOPT uses a feasible path method it will remain feasible throughout the optimization (unless the pre-processor destroys it, see section Iteration 1: Preprocessing in Appendix A).
If CONOPT has difficulties finding a feasible solution for your model you should try to use this technique to create an initial point in which as many equations as possible are satisfied. You may also try the optional Crash procedure described in section Preprocessing: The Optional Crash Procedure in Appendix A by adding the line lstcrs=t to the CONOPT options file. The crash procedure tries to identify equations with a mixture of uninitialized variables and variables with initial values, and it solves the equations with respect to the uninitialized variables; the effect is similar to the manual procedure shown above.
Bounds
Bounds have two purposes in nonlinear models. Some bounds represent constraints on the reality that is being modeled, e.g. a variable must be positive. These bounds are called model bounds. Other bounds help the algorithm by preventing it from moving far away from any optimal solution and into regions with singularities in the nonlinear functions or unreasonably large function or derivative values. These bounds are called algorithmic bounds.
Model bounds have natural roots and do not cause any problems. Algorithmic bounds require a closer look at the functional form of the model. The content of a Log should be greater than say 1.e-3, the content of an Exp should be less than 5 to 8, and a denominator should be greater than say 1.e-2. These recommended lower bounds of 1.e-3 and 1.e-2 may appear to be unreasonably large. However, both Log(x) and 1/x are extremely nonlinear for small arguments. The first and second derivatives of Log(x) at x=1.e-3 are 1.e+3 and -1.e6, respectively, and the first and second derivatives of 1/x at x=1.e-2 are -1.e+4 and 2.e+6, respectively.
If the content of a Log or Exp function or a denominator is an expression then it may be advantageous to introduce a bounded intermediate variable as discussed in the next section.
Note that bounds in some cases can slow the solution process down. Too many bounds may for example introduce degeneracy. If you have constraints of the following type
vub(i) .. x(i) =l= y;
or
ysum .. y =e= sum( i, x(i) );
and x is a Positive Variable then you should in general not declare y a Positive Variable or add a lower bound of zero on y. If y appears in a nonlinear function you may need a strictly positive bound. Otherwise, you should declare y a free variable; CONOPT will then make y basic in the initial point and y will remain basic throughout the optimization. New logic in CONOPT tries to remove this problem by detecting when a harmful bound is redundant so it can be removed, but it is not yet a fool proof procedure.
Section Iteration 1: Preprocessing in Appendix A gives another example of bounds that can be counter productive.
Simple Expressions
The following model component
Parameter mu(i); Variable x(i), s(i), obj; Equation objDef; objDef .. obj =e= Exp( Sum( i, Sqr( x(i) - mu(i) ) / s(i) ) );
can be re-written in the slightly longer but simpler form
Parameter mu(i); Pariable x(i), s(i), obj, inTerm; Equation intDef, objDef; intDef .. inTerm =e= Sum( i, Sqr( x(i) - mu(i) ) / s(i) ); objDef .. obj =e= Exp( inTerm );
The first formulation has very complex derivatives because Exp is taken of a long expression. The second formulation has much simpler derivatives; Exp is taken of a single variable, and the variables in intDef appear in a sum of simple independent terms.
In general, try to avoid nonlinear functions of expressions, divisions by expressions, and products of expressions, especially if the expressions depend on many variables. Define intermediate variables that are equal to the expressions and apply the nonlinear function, division, or product to the intermediate variable. The model will become larger, but the increased size is taken care of by CONOPT's sparse matrix routines, and it is compensated by the reduced complexity. If the model is solved with CONOPT using explicit second derivatives then simple expressions will result in sparser second derivatives that are both faster to compute and to use.
The reduction in complexity can be significant if an intermediate expression is linear. The following model fragment:
Variable x(i), y; Equation yDef; yDef .. y =e= 1 / Sum(i, x(i) );
should be written as
Variable x(i), xSum, y; Equation xSumDef, yDef; xSumDef .. xSum =e= Sum(i, x(i) ); yDef .. y =e= 1 / xSum; xSum.lo = 1.e-2;
for three reasons. First, because the number of nonlinear derivatives is reduced in number and complexity. Second, because the lower bound on the intermediate result will bound the search away from the singularity at xSum = 0. And third, because the matrix of second derivatives for the last model only depend on xSum while it depends on all x in the first model.
The last example shows an added potential saving by expanding functions of linear expressions. A constraint depends in a nonlinear fashion on the accumulated investments, inv, like
con(i) .. f( Sum( j$(ord(j) le ord(i)), inv(j) ) ) =l= b(i);
A new intermediate variable, cap(i), that is equal to the content of the Sum can be defined recursively with the constraints
cDef(i) .. cap(i) =e= inv(i) + cap(i-1);
and the original constraints become
con(i) .. f( cap(i) ) =l= b(i);
The reformulated model has n additional variables and n additional linear constraints. In return, the original n complex nonlinear constraints have been changed into n simpler nonlinear constraints. And the number of Jacobian elements, that has a direct influence on much of the computational work both in GAMS and in CONOPT, has been reduced from n*(n+1)/2 nonlinear elements to 3*n-1 linear elements and only n nonlinear element. If f is an invertible increasing function you may even rewrite the last constraint as a simple bound:
cap.lo(i) = finv(b(i));
Some NLP solvers encourage you to move as many nonlinearities as possible into the objective which may make the objective very complex. This is neither recommended nor necessary with CONOPT. A special pre-processing step (discussed in section Iteration 1: Preprocessing in Appendix A) will aggregate parts of the model if it is useful for CONOPT without increasing the complexity in GAMS.
Scaling
Nonlinear as well as Linear Programming Algorithms use the derivatives of the objective function and the constraints to determine good search directions, and they use function values to determine if constraints are satisfied or not. The scaling of the variables and constraints, i.e. the units of measurement used for the variables and constraints, determine the relative size of the derivatives and of the function values and thereby also the search path taken by the algorithm.
Assume for example that two goods of equal importance both cost $1 per kg. The first is measured in gram, the second in tons. The coefficients in the cost function will be $1000/g and $0.001/ton, respectively. If cost is measured in $1000 units then the coefficients will be 1 and 1.e-6, and the smaller may be ignored by the algorithm since it is comparable to some of the zero tolerances.
CONOPT assumes implicitly that the model to be solved is well scaled. In this context well scaled means:
- Basic and superbasic solution values are expected to be around 1, e.g. from 0.01 to 100. Nonbasic variables will be at a bound, and the bound values should not be larger than say 100.
- Dual variables (or marginals) on active constraints are expected to be around 1, e.g. from 0.01 to 100. Dual variables on non-binding constraints will of course be zero.
- Derivatives (or Jacobian elements) are expected to be around 1, e.g. from 0.01 to 100.
Variables become well scaled if they are measured in appropriate units. In most cases you should select the unit of measurement for the variables so their expected value is around unity. Of course there will always be some variation. Assume x(i) is the production at location i. In most cases you should select the same unit of measurement for all components of x, for example a value around the average capacity.
Equations become well scaled if the individual terms are measured in appropriate units. After you have selected units for the variables you should select the unit of measurement for the equations so the expected values of the individual terms are around one. If you follow these rules, material balance equations will usually have coefficients of plus and minus one.
Derivatives will usually be well scaled whenever the variables and equations are well scaled. To see if the derivatives are well scaled, run your model with a positive Option LimRow and look for very large or very small coefficients in the equation listing in the GAMS output file.
CONOPT computes a measure of the scaling of the Jacobian, both in the initial and in the final point, and if it seems large it will be printed. The message looks like:
** WARNING ** The variance of the derivatives in the initial
point is large (= 4.1 ). A better initial
point, a better scaling, or better bounds on the
variables will probably help the optimization.
The variance is computed as Sqrt(Sum(Log(Abs(jac(i)))**2)/nz) where jac(i) represents the nz nonzero derivatives (Jacobian elements) in the model. A variance of 4.1 corresponds to an average value of Log(jac)**2 of 4.1**2, which means that Jacobian values outside the range Exp(-4.1)=0.017 to Exp(+4.1)=60.4 are about as common at values inside. This range is for most models acceptable, while a variance of 5, corresponding to about half the derivatives outside the range Exp(-5)=0.0067 to Exp(+5)=148, can be dangerous.
Scaling of Intermediate Variables
Many models have a set of variables with a real economic or physical interpretation plus a set of intermediate or helping variables that are used to simplify the model. We have seen some of these in section Simple Expressions on Simple Expressions. It is usually rather easy to select good scaling units for the real variables since we know their order of magnitude from economic or physical considerations. However, the intermediate variables and their defining equations should preferably also be well scaled, even if they do not have an immediate interpretation. Consider the following model fragment where x, y, and z are variables and y is the intermediate variable:
Set p / p0*p4 / Parameter a(p) / p0 211, p1 103, p2 42, p3 31, p4 6 / yDef .. y =e= Sum(p, a(p)*Power(x,Ord(p)-1)); zDef .. z =e= Log(y);
x lies in the interval 1 to 10 which means that y will be between 211 and 96441 and Z will be between 5.35 and 11.47. Both x and z are reasonably scaled while y and the terms and derivatives in yDef are about a factor 1.e4 too large. Scaling y by 1.e4 and renaming it ys gives the following scaled version of the model fragment:
yDefs1 .. ys =e= Sum(p, a(p)*Power(x,Ord(p)-1))*1.e-4; zDefs1 .. z =e= Log(ys*1.e4);
The z equation can also be written as
zDefs2 .. z =e= Log(ys) + Log(1.e4);
Note that the scale factor 1.e-4 in the yDefs1 equation has been placed on the right hand side. The mathematically equivalent equation
yDefs2 .. ys*1.e4 =e= Sum(p, a(p)*Power(x,Ord(p)-1));
will give a well scaled YS, but the right hand side terms of the equation and their derivatives have not changed from the original equation yDef and they are still far too large.
Using the Scale Option in GAMS
The rules for good scaling mentioned above are exclusively based on algorithmic needs. GAMS has been developed to improve the effectiveness of modelers, and one of the best ways seems to be to encourage modelers to write their models using a notation that is as "natural" as possible. The units of measurement is one part of this natural notation, and there is unfortunately often a conflict between what the modeler thinks is a good unit and what constitutes a well scaled model.
To facilitate the translation between a natural model and a well scaled model GAMS has introduced the concept of a scale factor, both for variables and equations. The notation and the definitions are quite simple. First of all, scaling is by default turned off. To turn it on, enter the statement <model>.ScaleOpt = 1; in your GAMS program somewhere after the Model statement and before the Solve statement. <model> is the name of the model to be solved. If you want to turn scaling off again, enter the statement <model>.ScaleOpt = 0; somewhere before the next Solve.
The scale factor of a variable or an equation is referenced with the suffix ".Scale", i.e. the scale factor of variable x(i) is referenced as x.Scale(i). Note that there is one scale value for each individual component of a multidimensional variable or equation. Scale factors can be defined in assignment statements with x.Scale(i) on the left hand side, and scale factors, both from variables and equations, can be used on the right hand side, for example to define other scale factors. The default scale factor is always 1, and a scale factor must be positive; GAMS will generate an execution time error if the scale factor is less than 1.e-20.
The mathematical definition of scale factors is a follows: The scale factor on a variable,
This means, that if the variable scale,
This means, that if the equation scale,
The derivatives in the scaled model seen by the algorithm, i.e.
i.e. the modelers derivative is multiplied by the scale factor of the variable and divided by the scale factor of the equation. Note, that the derivative is unchanged if
G .. V =e= expression;
and you select
Scalar xRef; xRef = 6; y.Scale = Sum(p, a(p)*Power(xRef,Ord(p)-1)); yDef.Scale = y.Scale;
or we could scale
y.Scale = Max( Abs(Sum(p, a(p)*Power(x.Lo,Ord(p)-1))),
Abs(Sum(p, a(p)*Power(x.Up,Ord(p)-1))),
0.01 );
Lower and upper bounds on variables are automatically scaled in the same way as the variable itself. Integer and binary variables cannot be scaled.
GAMS' scaling is in most respects hidden for the modeler. The solution values reported back from a solution algorithm, both primal and dual, are always reported in the user's notation. The algorithm's versions of the equations and variables are only reflected in the derivatives in the equation and column listings in the GAMS output if Option LimRow and/or LimCol are positive, and in debugging output from the solution algorithm, generated with Option SysOut = On. In addition, the numbers in the algorithms iteration log will represent the scaled model: the infeasibilities and reduced gradients will correspond to the scaled model, and if the objective variable is scaled, the value of the objective function will be the scaled value.
A final warning about scaling of multidimensional variables is appropriate. Assume variable x(i,j,k) only appears in the model when the parameter ijk(i,j,k) is nonzero, and assume that Card(i) = Card(j) = Card(k) = 100 while Card(ijk) is much smaller than 100**2 = 1.e6. Then you should only scale the variables that appear in the model, i.e.
x.Scale(i,j,k)$ijk(i,j,k) = expression;
The statement
x.Scale(i,j,k) = expression;
will generate records for x in the GAMS database for all combinations of i, j, and k for which the expression is different from 1, i.e. up to 1.e6 records, and apart from spending a lot of time you will very likely run out of memory. Note that this warning also applies to non-default lower and upper bounds.
NLP and DNLP Models
GAMS has two classes of nonlinear model, NLP and DNLP. NLP models are defined as models in which all functions that appear with endogenous arguments, i.e. arguments that depend on model variables, are smooth with smooth derivatives. DNLP models can in addition use functions that are smooth but have discontinuous derivatives. The usual arithmetic operators (+, -, *, /, and **) can appear on both model classes.
The functions that can be used with endogenous arguments in a DNLP model and not in an NLP model are Abs, Min, and Max and as a consequence the indexed operators SMin and SMax.
Note that the offending functions can be applied to expressions that only involve constants such as parameters, var.l, and equ.m. Fixed variables are in principle constants, but GAMS makes its tests based on the functional form of a model, ignoring numerical parameter values and numerical bound values, and terms involving fixed variables can therefore not be used with Abs, Min, or Max in an NLP model.
The NLP solvers used by GAMS can also be applied to DNLP models. However, it is important to know that the NLP solvers attempt to solve the DNLP model as if it was an NLP model. The solver uses the derivatives of the constraints with respect to the variables to guide the search, and it ignores the fact that some of the derivatives may change discontinuously. There are at the moment no GAMS solvers designed specifically for DNLP models and no solvers that take into account the discontinuous nature of the derivatives in a DNLP model.
DNLP Models: What Can Go Wrong?
Solvers for NLP Models are all based on making marginal improvements to some initial solution until some optimality conditions ensure no direction with marginal improvements exist. A point with no marginally improving direction is called a Local Optimum.
The theory about marginal improvements is based on the assumption that the derivatives of the constraints with respect to the variables are a good approximations to the marginal changes in some neighborhood around the current point.
Consider the simple NLP model, Min Sqr(x), where x is a free variable. The marginal change in the objective is the derivative of Sqr(x) with respect to x, which is 2*x. At x = 0, the marginal change in all directions is zero and x = 0 is therefore a Local Optimum.
Next consider the simple DNLP model, Min Abs(x), where x again is a free variable. The marginal change in the objective is still the derivative, which is +1 if x > 0 and -1 if x < 0. When x = 0, the derivative depends on whether we are going to increase or decrease x. Internally in the DNLP solver, we cannot be sure whether the derivative at 0 will be -1 or +1; it can depend on rounding tolerances. An NLP solver will start in some initial point, say x = 1, and look at the derivative, here +1. Since the derivative is positive, x is reduced to reduce the objective. After some iterations, x will be zero or very close to zero. The derivative will be +1 or -1, so the solver will try to change x. however, even small changes will not lead to a better objective function. The point x = 0 does not look like a Local Optimum, even though it is a Local Optimum. The result is that the NLP solver will muddle around for some time and then stop with a message saying something like: "The solution cannot be improved, but it does not appear to be optimal."
In this first case we got the optimal solution so we can just ignore the message. However, consider the following simple two-dimensional DNLP model: Min Abs(x1+x2) + 5*Abs(x1-x2) with x1 and x2 free variables. Start the optimization from x1 = x2 = 1. Small increases in x1 will increase both terms and small decreases in x1 (by dx) will decrease the first term by dx but it will increase the second term by 5*dx. Any change in x1 only is therefore bad, and it is easy to see that any change in x2 only also is bad. An NLP solver may therefore be stuck in the point x1 = x2 = 1, even though it is not a local solution: the direction (dx1,dx2) = (-1,-1) will lead to the optimum in x1 = x2 = 0. However, the NLP solver cannot distinguish what happens with this model from what happened in the previous model; the message will be of the same type: "The solution cannot be improved, but it does not appear to be optimal."
Reformulation from DNLP to NLP
The only reliable way to solve a DNLP model is to reformulate it as an equivalent smooth NLP model. Unfortunately, it may not always be possible. In this section we will give some examples of reformulations.
The standard reformulation approach for the ABS function is to introduce positive and negative deviations as extra variables: The term z = Abs(f(x)) is replaced by z = fPlus + fMinus, fPlus and fMinus are declared as positive variables and they are defined with the identity: f(x) =e= fPlus - fMinus. The discontinuous derivative from the Abs function has disappeared and the part of the model shown here is smooth. The discontinuity has been converted into lower bounds on the new variables, but bounds are handled routinely by any NLP solver. The feasible space is larger than before; f(x) = 5 can be obtained both with fPlus = 5, fMinus = 0, and z = 5, and with fPlus = 1000, fMinus = 995, and z = 1995. Provided the objective function has some term that tries to minimize z, either fPlus or fMinus will become zero and z will end with its proper value.
You may think that adding the smooth constraint fPlus * fMinus =e= 0 would ensure that either fPlus or fMinus is zero. However, this type of so-called complementarity constraint is "bad" in any NLP model. The feasible space consists of the two half lines: (fPlus = 0 and fMinus
There is also a standard reformulation approach for the Max function. The equation z =e= Max(f(x),g(y)) is replace by the two inequalities, z =g= f(x) and z =g= g(y). Provided the objective function has some term that tries to minimize z, one of the constraints will become binding as equality and z will indeed be the maximum of the two terms.
The reformulation for the Min function is similar. The equation z =E= Min(f(x),g(y)) is replaced by the two inequalities, z =l= f(x) and z =l= g(y). Provided the objective function has some term that tries to maximize z, one of the constraints will become binding as equality and z is indeed the minimum of the two terms.
Max and Min can have more than two arguments and the extension should be obvious.
The non-smooth indexed operators, SMax and SMin can be handled using a similar technique: for example, z =E= SMax(i, f(x,i) ) is replaced by the indexed inequality: inEq(i) .. z =l= f(x,i);
The reformulations that are suggested here all enlarge the feasible space. They require the objective function to move the final solution to the intersection of this larger space with the original feasible space. Unfortunately, the objective function is not always so helpful. If it is not, you may try using one of the smooth approximations described next. However, you should realize, that if the objective function cannot help the "good" approximations described here, then your overall model is definitely non-convex and it is likely to have multiple local optima.
Smooth Approximations
Smooth approximations to the non-smooth functions ABS, MAX, and MIN are approximations that have function values close to the original functions, but have smooth derivatives.
A smooth GAMS approximation for Abs(f(x)) is
Sqrt( Sqr(f(x)) + Sqr(delta) )
where delta is a small scalar. The value of delta can be used to control the accuracy of the approximation and the curvature around f(x) = 0. The approximation error is largest when f(x) is zero, in which case the error is delta. The error is reduced to approximately Sqr(delta)/2 for f(x) = 1. The second derivative is 1/delta at f(x) = 0 (excluding terms related to the second derivative of f(x)). A delta value between 1.e-3 and 1.e-4 should in most cases be appropriate. It is possible to use a larger value in an initial optimization, reduce it and solve the model again. You should note, that if you reduce delta below 1.e-4 then large second order terms might lead to slow convergence or even prevent convergence.
The approximation shown above has its largest error when f(x) = 0 and smaller errors when f(x) is far from zero. If it is important to get accurate values of Abs exactly when f(x) = 0, then you may use the alternative approximation
Sqrt( Sqr(f(x)) + Sqr(delta) ) - delta
instead. The only difference is the constant term. The error is zero when f(x) is zero and the error grows to -delta when f(x) is far from zero.
Some theoretical work uses the Huber, H(*), function as an approximation for Abs. The Huber function is defined as
H(x) = x for x > delta, H(x) = -x for x < -delta and H(x) = Sqr(x)/2/delta + delta/2 for -delta < x < delta.
Although the Huber function has some nice properties, it is for example accurate when Abs(x) > delta, it is not so useful for GAMS work because it is defined with different formula for the three pieces.
A smooth GAMS approximation for Max(f(x),g(y)) is
( f(x) + g(y) + Sqrt( Sqr(f(x)-g(y)) + Sqr(delta) ) )/2
where delta again is a small scalar. The approximation error is delta/2 when f(x) = g(y) and decreases with the difference between the two terms. As before, you may subtract a constant term to shift the approximation error from the area f(x) = g(y) to areas where the difference is large. The resulting approximation becomes
( f(x) + g(y) + Sqrt( Sqr(f(x)-g(y)) + Sqr(delta) ) - delta )/2
Similar smooth GAMS approximations for Min(f(x),g(y)) are
( f(x) + g(y) - Sqrt( Sqr(f(x)-g(y)) + Sqr(delta) ) )/2
and
( f(x) + g(y) - Sqrt( Sqr(f(x)-g(y)) + Sqr(delta) ) + delta )/2
Appropriate delta values are the same as for the Abs approximation: in the range from 1.e-2 to 1.e-4.
It appears that there are no simple symmetric extensions for Max and Min of three or more arguments or for indexed SMax and SMin.
Are DNLP Models Always Non-smooth?
A DNLP model is defined as a model that has an equation with an Abs, Max, or Min function with endogenous arguments. The non-smooth properties of DNLP models are derived from the non-smooth properties of these functions through the use of the chain rule. However, composite expressions involving Abs, Max, or Min can in some cases have smooth derivatives and the model can therefore in some cases be smooth.
One example of a smooth expression involving an Abs function is common in water systems modeling. The pressure loss over a pipe, dH, is proportional to the flow, Q, to some power, P. P is usually around +2. The sign of the loss depend on the direction of the flow so dH is positive if Q is positive and negative if Q is negative. Although GAMS has a Sign function, it cannot be used in a model because of its discontinuous nature. Instead, the pressure loss can be modeled with the equation dH =E= const * Q * Abs(Q)**(P-1), where the sign of the Q-term takes care of the sign of dH, and the Abs function guaranties that the real power ** is applied to a non-negative number. Although the expression involves the Abs function, the derivatives are smooth as long as P is greater than 1. The derivative with respect to Q is const * (P-1) * Abs(Q)**(P-1) for Q > 0 and -const * (P-1) * Abs(Q)**(P-1) for Q < 0. The limit for Q going to zero from both right and left is 0, so the derivative is smooth in the critical point Q = 0 and the overall model is therefore smooth.
Another example of a smooth expression is the following terribly looking Sigmoid expression:
Sigmoid(x) = Exp( Min(x,0) ) / (1+Exp(-Abs(x)))
The standard definition of the sigmoid function is
Sigmoid(x) = Exp(x) / ( 1+Exp(x) )
This definition is well behaved for negative and small positive x, but it not well behaved for large positive x since Exp overflows. The alternative definition:
Sigmoid(x) = 1 / ( 1+Exp(-x) )
is well behaved for positive and slightly negative x, but it overflows for very negative x. Ideally, we would like to select the first expression when x is negative and the second when x is positive, i.e.
Sigmoid(x) = (Exp(x)/(1+Exp(x)))$(x < 0) + (1/(1+Exp(-x)))$(x > 0)
but a $ -control that depends on an endogenous variable is illegal. The first expression above solves this problem. When x is negative, the nominator becomes Exp(x) and the denominator becomes 1+Exp(x). And when x is positive, the nominator becomes Exp(0) = 1 and the denominator becomes 1+Exp(-x). Since the two expressions are mathematically identical, the combined expression is of course smooth, and the Exp function is never evaluated for a positive argument.
Unfortunately, GAMS cannot recognize this and similar special cases so you must always solve models with endogenous Abs, Max, or Min as DNLP models, even in the cases where the model is smooth.
Are NLP Models Always Smooth?
NLP models are defined as models in which all operators and functions are smooth. The derivatives of composite functions, that can be derived using the chain rule, will therefore in general be smooth. However, it is not always the case. The following simple composite function is not smooth: y = Sqrt( Sqr(x) ). The composite function is equivalent to y = Abs(x), one of the non-smooth DNLP functions.
What went wrong? The chain rule for computing derivatives of a composite function assumes that all intermediate expressions are well defined. However, the derivative of Sqrt grows without bound when the argument approaches zero, violating the assumption.
There are not many cases that can lead to non-smooth composite functions, and they are all related to the case above: The real power, x**y, for 0 < y < 1 and x approaching zero. The Sqrt function is a special case since it is equivalent to x**y for y = 0.5.
If you have expressions involving a real power with an exponent between 0 and 1 or a Sqrt, you should in most cases add bounds to your variables to ensure that the derivative or any intermediate terms used in their calculation become undefined. In the example above, Sqrt( Sqr(x) ), a bound on x is not possible since x should be allowed to be both positive and negative. Instead, changing the expression to Sqrt( Sqr(x) + Sqr(delta)) may lead to an appropriate smooth formulation.
Again, GAMS cannot recognize the potential danger in an expression involving a real power, and the presence of a real power operator is not considered enough to flag a model as a DNLP model. During the solution process, the NLP solver will compute constraint values and derivatives in various points within the bounds defined by the modeler. If these calculations result in undefined intermediate or final values, a function evaluation error is reported, an error counter is incremented, and the point is flagged as a bad point. The following action will then depend on the solver. The solver may try to continue, but only if the modeler has allowed it with an Option DomLim = xxx;. The problem of detecting discontinuities is changed from a structural test at the GAMS model generation stage to a dynamic test during the solution process.
You may have a perfectly nice model in which intermediate terms become undefined. The composite function Sqrt( Power(x,3) ) is mathematically well defined around x = 0, but the computation will involve the derivative of Sqrt at zero, that is undefined. It is the modeler's responsibility to write expressions in a way that avoids undefined intermediate terms in the function and derivatives computations. In this case, you may either add a small strictly positive lower bound on x or rewrite the function as x**1.5
APPENDIX A: Algorithmic Information
The objective of this Appendix is to give technically oriented users some understanding of what CONOPT is doing so they can get more information out of the iteration log. This information can be used to prevent or circumvent algorithmic difficulties or to make informed guesses about which options to experiment with to improve CONOPT's performance on particular model classes.
Overview of CONOPT
CONOPT is a GRG-based algorithm specifically designed for large nonlinear programming problems expressed in the following form
min or max f(x) (1) subject to g(x) = b (2) lo < x < up (3)
where x is the vector of optimization variables, lo and up are vectors of lower and upper bounds, some of which may be minus or plus infinity, b is a vector of right hand sides, and f and g are differentiable nonlinear functions that define the model. n will in the following denote the number of variables and m the number of equations. (2) will be referred to as the (general) constraints and (3) as the bounds.
The relationship between the mathematical model in (1)-(3) above and the GAMS model is simple: The inequalities defined in GAMS with =l= or =g= are converted into equalities by addition of properly bounded slacks. Slacks with lower and upper bound of zero are added to all GAMS equalities to ensure that the Jacobian matrix, i.e. the matrix of derivatives of the functions g with respect to the variables x, has full row rank. All these slacks are together with the normal GAMS variables included in x. lo represent the lower bounds defined in GAMS, either implicitly with the Positive Variable declaration, or explicitly with the Var.Lo notation, as well as any bounds on the slacks. Similarly, up represent upper bounds defined in GAMS, e.g. with the Var.Up notation, as well as any bounds on the slacks. g represent the non-constant terms of the GAMS equations themselves; non-constant terms appearing on the right hand side are by GAMS moved to the left hand side and constant terms on the left hand side are moved to the right. The objective function f is simply the GAMS variable to be minimized or maximized.
Additional comments on assumptions and design criteria can be found in the Introduction to the main text.
The CONOPT Algorithm
The algorithm used in CONOPT is based on the GRG algorithm first suggested by Abadie and Carpentier (1969). The actual implementation has many modifications to make it efficient for large models and for models written in the GAMS language. Details on the algorithm can be found in Drud (1985 and 1992). Here we will just give a short verbal description of the major steps in a generic GRG algorithm. The later sections in this Appendix will discuss some of the enhancements in CONOPT that make it possible to solve large models.
The key steps in any GRG algorithm are:
- Initialize and Find a feasible solution.
- Compute the Jacobian of the constraints,
- Select a set of
- Solve
- Compute the reduced gradient,
- If
- Select the set of superbasic variables,
- Perform a line search along the direction
- Go to 2.
The individual steps are of course much more detailed in a practical implementation like CONOPT. Step 1 consists of several pre-processing steps as well as a special Phase 0 and a scaling procedure as described in the following sections Iteration 0: The Initial Point to Finding a Feasible Solution: Phase 0 . The optimizing steps are specialized in several versions according to the whether the model appears to be almost linear or not. For "almost" linear models some of the linear algebra work involving the matrices
The remaining two sections give some short guidelines for selecting non-default options (section How to Select Non-default Options), and discuss miscellaneous topics (section Miscellaneous Topics) such as CONOPT's facilities for strictly triangular models (section Triangular Models) and for square systems of equations, in GAMS represented by the model class called CNS or Constrained Nonlinear System (section Constrained Nonlinear System or Square Systems of Equations), as well as numerical difficulties due to loss of feasibility (section Loss of Feasibility) and slow or no progress due to stalling (section Stalling).
Iteration 0: The Initial Point
The first few "iterations" in the iteration log (See section Iteration Output ), in the main text for an example) are special initialization iterations, but they have been counted as real iterations to allow the user to interrupt at various stages during initialization. Iteration 0 corresponds to the input point exactly as it was received from GAMS. The sum of infeasibilities in the column labeled "Infeasibility" includes all residuals, also from the objective constraint where "z
=e= expression" will give rise to the term Abs( z - expression ) that may be nonzero if z has not been initialized. You may stop CONOPT after iteration 0 with Option IterLim = 0; in GAMS. The solution returned to GAMS will contain the input point and the values of the constraints in this point. The marginals of both variables and equations have not yet been computed and they will be returned as EPS.
This possibility can be used for debugging when you have a reference point that should be feasible, but is infeasible for unknown reasons. Initialize all variables to their reference values, also all intermediate variables, and call CONOPT with IterLim = 0. Then compute and display the following measures of infeasibility for each block of constraints, represented by the generic name eq:
=e= constraints: Round(Abs(eq.L - eq.Lo),3) =l= constraints: Round(Min(0,eq.L - eq.Up),3) =g= constraints: Round(Min(0,eq.Lo - eq.L),3)
The Round function rounds to 3 decimal places so GAMS will only display the infeasibilities that are larger than 5.e-4.
Similar information can be derived from inspection of the equation listing generated by GAMS with Option LimRow = nn;, but although the method of going via CONOPT requires a little more work during implementation it can be convenient in many cases, for example for large models and for automated model checking.
Iteration 1: Preprocessing
Iteration 1 corresponds to a pre-processing step. Constraint-variable pairs that can be solved a priori (so-called pre-triangular equations and variables) are solved and the corresponding variables are assigned their final values. Constraints that always can be made feasible because they contain a free variable with a constant coefficient (so-called post-triangular equation-variable pairs) are excluded from the search for a feasible solution and from the Infeasibility measure in the iteration log. Implicitly, equations and variables are ordered as shown in Figure 1.
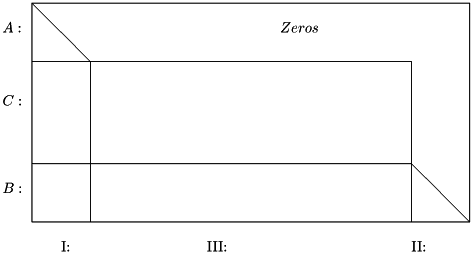
Preprocessing: Pre-triangular Variables and Constraints
The pre-triangular equations are those labeled A in Figure 1. They are solved one by one along the "diagonal" with respect to the pre-triangular variables labeled I. In practice, CONOPT looks for equations with only one non-fixed variable. If such an equation exists, CONOPT tries to solve it with respect to this non-fixed variable. If this is not possible the overall model is infeasible, and the exact reason for the infeasibility is easy to identify as shown in the examples below. Otherwise, the final value of the variable has been determined, the variable can for the rest of the optimization be considered fixed, and the equation can be removed from further consideration. The result is that the model has one equation and one non-fixed variable less. As variables are fixed new equations with only one non-fixed variable may emerge, and CONOPT repeats the process until no more equations with one non-fixed variable can be found.
This pre-processing step will often reduce the effective size of the model to be solved. Although the pre-triangular variables and equations are removed from the model during the optimization, CONOPT keeps them around until the final solution is found. The dual variables for the pre-triangular equations are then computed so they become available in GAMS.
CONOPT has a special option for analyzing and solving completely triangular models. This option is described in section Triangular Models .
The following small GAMS model shows an example of a model with pre-triangular variables and equations:
Variable x1, x2, x3, obj; Equation e1, e2, e3; e1 .. Log(x1) + x2 =e= 1.6; e2 .. 5 * x2 =e= 3; e3 .. obj =e= Sqr(x1) + 2 * Sqr(x2) + 3 * Sqr(x3); x1.Lo = 0.1; Model demo / All /; Solve demo using NLP Minimizing obj;
Equation e2 is first solved with respect to x2 (result 3/5 = 0.6). It is easy to solve the equation since x2 appears linearly, and the result will be unique. x2 is then fixed and the equation is removed. Equation e1 is now a candidate since x1 is the only remaining non- fixed variable in the equation. Here x1 appears nonlinear and the value of x1 is found using an iterative scheme based on Newton's method. The iterations are started from the value provided by the modeler or from the default initial value. In this case x1 is started from the default initial value, i.e. the lower bound of 0.1, and the result after some iterations is x1 = 2.718 = Exp(1).
During the recursive solution process it may not be possible to solve one of the equations. If the lower bound on x1 in the model above is changed to 3.0 you will get the following output:
** An equation in the pre-triangular part of the model cannot
be solved because the critical variable is at a bound.
Residual= 9.86122887E-02
Tolerance (RTNWTR)= 6.34931126E-07
e1: Infeasibility in pre-triangular part of model.
x1: Infeasibility in pre-triangular part of model.
The solution order of the critical equations and
variables is:
e2 is solved with respect to
x2. Solution value = 6.0000000000E-01
e1 could not be solved with respect to
x1. Final solution value = 3.0000000000E+00
e1 remains infeasible with residual = 9.8612288668E-02
The problem is as indicated that the variable to be solved for is at a bound, and the value suggested by Newton's method is on the infeasible side of the bound. The critical variable is x1 and the critical equation is e1, i.e. x1 tries to exceed its bound when CONOPT solves equation e1 with respect to x1. To help you analyze the problem, especially for larger models, CONOPT reports the solution sequence that led to the infeasibility: In this case equation e2 was first solved with respect to variable x2, then equation e1 was attempted to be solved with respect to x1 at which stage the problem appeared. To make the analysis easier CONOPT will always report the minimal set of equations and variables that caused the infeasibility.
Another type of infeasibility is shown by the following model:
Variable x1, x2, x3, obj; Equation e1, e2, e3; e1 .. Sqr(x1) + x2 =e= 1.6; e2 .. 5 * x2 =e= 3; e3 .. obj =e= Sqr(x1) + 2 * Sqr(x2) + 3 * Sqr(x3); Model demo / All /; Solve demo using NLP Minimizing obj;
where Log(x1) has been replaced by Sqr(x1) and the lower bound on x1 has been removed. This model gives the message:
** An equation in the pre-triangular part of the model cannot
be solved because of too small pivot.
Adding a bound or initial value may help.
Residual= 4.0000000
Tolerance (RTNWTR)= 6.34931126E-07
e1: Infeasibility in pre-triangular part of model.
x1: Infeasibility in pre-triangular part of model.
The solution order of the critical equations and
variables is:
e2 is solved with respect to
x2. Solution value = 6.0000000000E-01
e1 could not be solved with respect to
x1. Final solution value = 0.0000000000E+00
e1 remains infeasible with residual =-4.0000000000E+00
After equation e2 has been solved with respect to x2, equation e1 that contains the term Sqr(x) should be solved with respect to x1. The initial value of x1 is the default value zero. The derivative of e1 with respect to x1 is therefore zero, and it is not possible for CONOPT to determine whether to increase or decrease x1. If x1 is given a nonzero initial value the model will solve. If x1 is given a positive initial value the equation will give x1 = 1, and if x1 is given a negative initial value the equation will give x1 = -1. The last type of infeasibility that can be detected during the solution of the pre-triangular or recursive equations is shown by the following example
Variable x1, x2, x3, obj; Equation e1, e2, e3; e1 .. Log(x1) + x2 =e= 1.6; e2 .. 5 * x2 =e= 3; e3 .. obj =e= Sqr(x1) + 2 * Sqr(x2) + 3 * Sqr(x3); e4 .. x1 + x2 =e= 3.318; x1.Lo = 0.1; Model demo / All /; Solve demo using NLP Minimizing obj;
that is derived from the first model by the addition of equation e4. This model produces the following output
** An equation is inconsistent with other equations in the
pre-triangular part of the model.
Residual= 2.81828458E-04
Tolerance (RTNWTR)= 6.34931126E-07
The pre-triangular feasibility tolerance may be relaxed with
a line:
SET RTNWTR X.XX
in the CONOPT control program.
e4: Inconsistency in pre-triangular part of model.
The solution order of the critical equations and
variables is:
e2 is solved with respect to
x2. Solution value = 6.0000000000E-01
e1 is solved with respect to
x1. Solution value = 2.7182818285E+00
All variables in equation e4 are now fixed
and the equation is infeasible. Residual = 2.8182845830E-04
First e2 is solved with respect to x2, then e1 is solved with respect to x1 as indicated by the last part of the output. At this point all variables that appear in equation e4, namely x1 and x2, are fixed, but the equation is not feasible. e4 is therefore inconsistent with e1 and e2 as indicated by the first part of the output. In this case the inconsistency is fairly small, 2.8E-04, so it could be a tolerance problem. CONOPT will always report the tolerance that was used, rtnwtr - the triangular Newton tolerance, and if the infeasibility is small it will also tell how the tolerance can be relaxed. Section The CONOPT Options File gives further details on how to change tolerances, and a complete list of options is given in Appendix B.
You can turn the identification and solution of pre-triangular variables and equations off by adding the line lspret = f in the CONOPT control program. This can be useful in some special cases where the point defined by the pre-triangular equations gives a function evaluation error in the remaining equations. The following example shows this:
Variable x1, x2, x3, x4, obj; Equation e1, e2, e3, e4; e1 .. Log(1+x1) + x2 =e= 0; e2 .. 5 * x2 =e= -3; e3 .. obj =e= 1*Sqr(x1) + 2*Sqrt(0.01 + x2 - x4) + 3*Sqr(x3); e4 .. x4 =l= x2; MOdel fer / All /; Solve fer Minimizing obj using NLP;
All the nonlinear functions are defined in the initial point in which all variables have their default value of zero. The pre-processor will compute x2 = -0.6 from e2 and x1 = 0.822 from e1. When CONOPT continues and attempts to evaluate e3, the argument to the Sqrt function is negative when these new triangular values are used together with the initial x4 = 0, and CONOPT cannot backtrack to some safe point since the function evaluation error appears the first time e3 is evaluated. When the pre-triangular preprocessor is turned off, x2 and x4 are changed at the same time and the argument to the Sqrt function remains positive throughout the computations. Note, that although the purpose of the e4 inequality is to guarantee that the argument of the Sqrt function is positive in all points, and although e4 is satisfied in the initial point, it is not satisfied after the pre-triangular constraints have been solved. Only simple bounds are strictly enforced at all times. Also note that if the option lspret = f is used then feasible linear constraints will in fact remain feasible.
An alternative (and preferable) way of avoiding the function evaluation error is to define an intermediate variable equal to 0.01+x2-x4 and add a lower bound of 0.01 on this variable. The inequality e4 could then be removed and the overall model would have the same number of constraints.
Preprocessing: Post-triangular Variables and Constraints
Consider the following fragment of a larger GAMS model:
Variable util(t) Utility in period t
totutil Total Utility;
Equation utilDef(T) Definition of Utility
tutilDef Definition of Total Utility;
utilDef(T).. util(t) =e= nonlinear function of other variables;
tutilDef .. totutil =e= Sum( t , util(t) / (1+r)**Ord(t) );
Model demo / All /; Solve demo Maximizing totutil using NLP;
The part of the model shown here is easy to read and from a modeling point of view it should be considered well written. However, it could be more difficult to solve than a model in which variable util(t) was substituted out because all the utilDef equations are nonlinear constraints that the algorithms must ensure are satisfied.
To make well written models like this easy to solve CONOPT will move as many nonlinearities as possible from the constraints to the objective function. This automatically changes the model from the form that is preferable for the modeler to the form that is preferable for the algorithm. In this process CONOPT looks for free variables that only appear in one equation outside the objective function. If such a variable exists and it appears linearly in the equation, like util(t) appears with coefficient 1 in equation utilDef(t), then the equation can always be solved with respect to the variable. This means that the variable logically can be substituted out of the model and the equation can be removed. The result is a model that has one variable and one equation less, and a more complex objective function. As variables and equations are substituted out, new candidates for elimination may emerge, so CONOPT repeats the process until no more candidates exist.
This so-called post-triangular preprocessing step will often move several nonlinear constraints into the objective function where they are much easier to handle, and the effective size of the model will decrease. In some cases the result can even be a model without any general constraints. The name post-triangular is derived from the way the equations and variables appear in the permuted Jacobian in Figure 1. The post-triangular equations and variables are the ones on the lower right hand corner labeled B and II, respectively.
In the example above, the util variables will be substituted out of the model together with the nonlinear utilDef equations provided the util variables are free and do not appear elsewhere in the model. The resulting model will have fewer nonlinear constraints, but more nonlinear terms in the objective function.
Although you may know that the nonlinear functions on the right hand side of utilDef always will produce positive util values, you should in general not declare util to be a Positive Variable. If you do, CONOPT may not be able to eliminate util(t), and the model will be harder to solve. It is of course unfortunate that a redundant bound changes the solution behavior, and to reduce this problem CONOPT will try to estimate the range of nonlinear expressions using interval arithmetic. If the computed range of the right hand side of the utilDef constraint is within the bounds of util, then these bounds cannot be binding and util is a so-called implied free variable that can be eliminated.
The following model fragment from a least squares model shows another case where the preprocessing step in CONOPT is useful:
Variable residual(case) Residuals
ssq Sum of Squared Residuals;
Equation eqEst(case) Equation to be estimated
ssqDef Definition of objective;
eqEst(case).. residual(case) =e= expression in other variables;
SSQDEF .. ssq =e= Sum( case, Sqr( residual(case) ) );
Model lsqLarge / All /; Solve lsqLarge using NLP Minimizing ssq;
CONOPT will substitute the residual variables out of the model using the eqEst equations. The model solved by CONOPT is therefore mathematically equivalent to the following GAMS model
Variable ssq Sum of Squared Residuals; Equation ssqd Definition of objective; Ssqd .. ssq =e= Sum( case, Sqr(expression in other variables)); Model lsqSmall / All /; Solve lsqSmall using NLP Minimizing ssq;
However, if the "expression in other variables" is a little complicated, e.g. if it depends on several variables, then the first model, lsqLarge, will be much faster to generate with GAMS because its derivatives in equation qEst and ssqDef are much simpler than the derivatives in the combined ssqd equation in the second model, lsqSmall. The larger model will therefore be faster to generate, and it will also be faster to solve because the computation of both first and second derivatives will be faster.
Note that the comments about what are good model formulations are dependent on the preprocessing capabilities in CONOPT. Other algorithms may prefer models like lsqSmalL over lsqLarge. Also note that the variables and equations that are substituted out are still indirectly part of the model. CONOPT evaluates the equations and computes values for the variables each time the value of the objective function is needed, and their values are available in the GAMS solution.
It is not necessary to have a coefficient of 1 for the variable to be substituted out in the post-triangular phase. However, a non-zero coefficient cannot be smaller than the absolute pivot tolerance used by CONOPT, rtpiva.
The number of pre- and post-triangular equations and variables is printed in the log file between iteration 0 and 1 as shown in the iteration log in section Iteration Output of the main text. The sum of infeasibilities will usually decrease from iteration 0 to 1 because fewer constraints usually will be infeasible. However, it may increase as shown by the following example:
Positive Variable x, y, z; Equation e1, e2; e1.. x =e= 1; e2.. 10*x - y + z =e= 0;
started from the default values x.L = 0, y.L = 0, and z.L = 0. The initial sum of infeasibilities is 1 (from e1 only). During pre-processing x is selected as a pre-triangular variable in equation e1 and it is assigned its final value 1 so e1 becomes feasible. After this change the sum of infeasibilities increases to 10 (from e2 only).
You may stop CONOPT after iteration 1 with Option IterLim = 1; in GAMS. The solution returned to GAMS will contain the pre-processed values for the variables that can be assigned values from the pre-triangular equations, the computed values for the variables used to solve the post-triangular equations, and the input values for all other variables. The pre- and post-triangular constraints will be feasible, and the remaining constraints will have values that correspond to this point. The marginals of both variables and equations have not been computed yet and will be returned as EPS.
The crash procedure described in the following sub-section is an optional part of iteration 1.
Preprocessing: The Optional Crash Procedure
In the initial point given to CONOPT the variables are usually split into a group with initial value provided by the modeler (in the following called the assigned variables) and a group of variables for which no initial value has been provided (in the following called the default variables). The objective of the optional crash procedure is to find a point in which as many of the constraints as possible are feasible, primarily by assigning values to the default variables and by keeping the assigned variables at their initial values. The implicit assumption in this procedure is that if the modeler has assigned an initial value to a variable then this value is "better" then a default initial value.
The crash procedure is an extension of the triangular pre-processing procedure described above and is based on a simple heuristic: As long as there is an equation with only one non-fixed variable (a singleton row) then we should assign a value to the variable so the equation is satisfied or satisfied as closely as possible, and we should then temporarily fix the variable. When variables are fixed additional singleton rows may emerge and we repeat the process. When there are no singleton rows we fix one or more variables at their initial value until a singleton row appears, or until all variables have been fixed. The variables to be fixed at their initial value are selected using a heuristic that both tries to create many row singletons and tries to select variables with "good values". Since the values of many variables will come to depend in the fixed variables, the procedure favors assigned variables and among these it favors variables that appear in many feasible constraints.
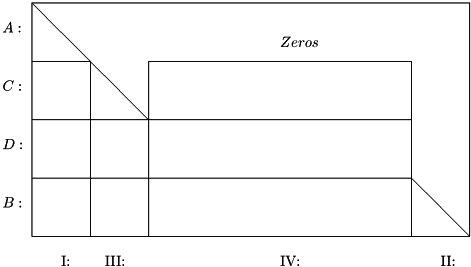
Figure 2 shows a reordered version of Figure 1. The variables labeled IV are the variables that are kept at their initial values, primarily selected from the assigned variables. The equations labeled C are then solved with respect to the variables labeled III, called the crash-triangular variables. The crash-triangular variables will often be variables without initial values, e.g. intermediate variables. The number of crash-triangular variables is shown on the iteration output between iteration 0 and 1, but only if the crash procedure is turned on.
The result of the crash procedure is an updated initial point in which usually a large number of equations will be feasible, namely all equations labeled A, B, and C in Figure 2. There is, as already shown with the small example in Section Preprocessing: Post-triangular Variables and Constraints above, no guarantee that the sum of infeasibilities will be reduced, but it is often the case, and the point will often provide a good starting point for the following procedures that finds an initial feasible solution.
The crash procedure is activated by adding the line lstcrs=t in the options file. The default value of lstcrs (lstcrs = Logical Switch for Triangular Crash) is f or false, i.e. the crash procedure is not normally used. Before turning the crash procedure on you must turn the definitional equations (see next sub-section) off.
Preprocessing: Definitional Equations
From version 3.16 CONOPT has introduced the concept of Definitional Equations. In section Simple Expressions it was recommended to introduce intermediate variables to simplify complex expressions. If the intermediate variables are free or if the bounds defined by the modeler cannot be binding then we call the constraints that define the intermediate variables "Definitional Equations" and the intermediate variables "Defined Variables". Some models have a large number of definitional equations, and CONOPT tries to recognize them and take advantage of the special structure. Defined variables that only appear in or feed into the objective are recognized as post-triangular variables as discussed in section Preprocessing: Post-triangular Variables and Constraints but defined variables can also be used in the simultaneous constraints. The picture is similar to fig 2. with the C-rows representing the definitional constraints and the III-variables the defined variables. The main differences between crash- triangular variables and defined variable are that (1) defined variables are free or have non-binding bounds and the definitional equations can therefore always be made feasible, (2) defined variables are cheaper to recognize, (3) since they have a natural interpretation, using them is probably more numerical stable, and (4) there are most likely fewer defined variables than crash-triangular variables.
The number of definitional equations is printed in the log file between iteration 0 and 1 if CONOPT finds any. The definitional equations are used to give the defined variables new values, so it is no longer so important the give intermediate variables initial values. In the process the sum of infeasibilities may grow but CONOPT consider it more important to keep these constraints feasible. The defined variables are also made basic and they will most likely stay basic throughout the solution process.
There are three new options introduced to controls the detection of definitional equations: lsusdf, lsuqdf, and lfusdf. They are described in Appendix B. By default CONOPT will only look for unique definitional constraints, but the options allow the user to experiment with a more aggressive strategy.
From version 3.16F there is an additional option, lmusdf, used to control how the definitional equations are used during the optimization. The option is summarized in Appendix B. By default, definitional equations are only used to define initial values and an initial basis and their special properties are ignored during the optimization. If there are many definitional equations and they are fairly nonlinear then it can sometimes be beneficial to force the definitional variables to remain basic and to use the definitional equations to compute values for the defined variables in all intermediate trial points. This behavior is turned on with lmusdf = 1. The point where lmusdf = 1 start to pay off depends on the model and the degree of nonlinearity, but a guess is that the number of definitional equations should exceed half the number of equations remaining after the pre- and post-triangular equations have been removed before it is worth while.
Preprocessing and Function evaluation errors
Function evaluation errors may occure during pre-processing is an equation that is a candidate for becoming pre-triangular. Since GAMS requires all functions to be defined in the starting point this can only happen if a previously solved pre-triangular variable has recived new a value that makes the function undefined. An example is:
positive variable x1, x2 equation e1, e2; e1 .. x1 =E= 10; e2 .. x2 =E= log( 5-x1 );
The pre-triangular variable x1 is changed to 10, a value that is inconsistent with equation e2. You can see the changes that CONOPT has made during pre-processing with the option prprec = true and this should help identify why the model does not solve.
After identifying and solving the pre-triangular part of the model CONOPT looks for implied bounds, and if an initial variable violates such an implied bound, CONOPT will move it inside the bound. This change can give rise to a function evaluation error in one of the remaining constraints. An example is:
positive variable x1, x2, x3, x4; equation e1, e2; e1.. x1 + x2 =L= 10; e2.. x4 =E= log(x1+x3-20); x1.l = 100; x3.up = 100;
From constraint e1 we can derive that both x1 and x2 must have (implied) upper bounds of 10. Since the initial value of x1 is above this implied bound it is changed by the pre-processor. After the pre-processor finishes, e2 will give a function evaluation error. Again, option prprec = true will give output that describes the changes in the variables which should help identify the problem.
Iteration 2: Scaling
Iteration 2 is the last dummy iteration during which the model is scaled, if scaling is turned on. The default is to turn scaling on. The Infeasibility column shows the scaled sum of infeasibilities. You may again stop CONOPT after iteration 2 with Option IterLim = 2; in GAMS, but the solution that is reported in GAMS will have been scaled back again so there will be no change from iteration 1 to iteration 2.
The following description of the automatic scaling procedure is included for completeness. Experiments have so far given mixed results with some advantage for scaling, and scaling is therefore by default turned on, corresponding to the CONOPT option lsscal = t. Users are recommended to be cautious with the automatic scaling procedure. If scaling is a problem, try to use manual scaling or scaling in GAMS (see section Scaling in the main text) based on an understanding of the model.
The scaling procedure multiplies all variables in group III and all constraints in group C (see Figure 1) by scale factors computed as follows:
- CONOPT computes the largest term for each constraint, i. This is defined as the maximum of the constant right hand side, the slack (if any), and Abs(jac(i,j)*x(j)) where jac(i,j) is the derivative and x(j) is the variable.
- The constraint scale factor is defined as the largest term in the constraint, projected on the interval
[rtmins, rtmaxs]. The constraint is then divided by the constraint scale factor. Ignoring the projection, the result is a model in which the largest term in each constraint is exactly 1. The purpose of the projection is to prevent extreme scaling. The default value ofrtminsis 1 which implies that we do not scale the constraints up. Constraints with only small terms remain unchanged. The default value ofrtmaxsis 2**30 or around 1.07e9 so terms much larger than 1.e9 are only partially scaled down and will still remain large. - The terms Abs(jac(i,j)*x(j)) after constraint scaling measure the importance of each variable in the particular constraint. The variable scale is selected so the largest importance of the variable over all constraints is 1. This gives a very simple variable scale factor, namely the absolute value of the variable. The variable is then divided by the variable scale factor. To avoid extreme scaling we again project on the interval
[rtmins, rtmaxs]. Variables less thanrtmins(default 1) are therefore not scaled up and variables overrtmaxs(default 2**30 = 1.07e9) are only partially scaled down.
You should note that CONOPT by default scales large numbers down, but it does not scale small numbers up. You should therefore try to avoid having variables or terms in expressions that are small but significant. If this is not possible, allow CONOPT to scale up by giving the option rtmins a value less than 1.
All scale factors are rounded down to a power of 2 to preserve precision in the internal computations. To avoid difficulties with rapidly varying variables and derivatives CONOPT recomputes the scale factors at regular intervals (see lfscal).
The options that control scaling, lsscal, lfscal, rtmins, and rtmaxs, are all described in Appendix B.
Finding a Feasible Solution: Phase 0
The GRG algorithm used by CONOPT is a feasible path algorithm. This means that once it has found a feasible point it tries to remain feasible and follow a path of improving feasible points until it reaches a local optimum. CONOPT starts with the point provided by GAMS. This point will always satisfy the bounds (3): GAMS will simply move a variable that is outside its bounds to the nearer bound before it is presented to the solver. If the general constraints (2) also are feasible then CONOPT will work with feasible solutions throughout the optimization. However, the initial point may not satisfy the general constraints (2). If this is not the case, CONOPT must first find an initial feasible point. This first step can be just as hard as finding an optimum for some models. For some models feasibility is the only problem.
CONOPT has two methods for finding an initial feasible point. The first method is not very reliable but it is fast when it works; the second method is reliable but slower. The fast method is called Phase 0 and it is described in this section. It is used first. The reliable method, called Phase 1 and 2, will be used if Phase 0 terminates without a feasible solution.
Phase 0 is based on the observation that Newton's method for solving a set of equations usually is very fast, but it may not always converge. Newton's method in its pure form is defined for a model with the same number of variables as equations, and no bounds on the variables. With our type of model there are usually too many variables, i.e. too many degrees of freedom, and there are bounds. To get around the problem of too many variables, CONOPT selects a subset with exactly m "basic" variables to be changed. The rest of the variables will remain fixed at their current values, that are not necessarily at bounds. To accommodate the bounds, CONOPT will try to select variables that are away from their bounds as basic, subject to the requirement that the Basis matrix, consisting of the corresponding columns in the Jacobian, must have full rank and be well conditioned.
The Newton equations are solved to yield a vector of proposed changes for the basic variables. If the full proposed step can be applied we can hope for the fast convergence of Newton's method. However, several things may go wrong:
- The infeasibilities, measured by the 1-norm of g (i.e. the sum of the absolute infeasibilities, excluding the pre- and post-triangular equations), may not decrease as expected due to nonlinearities.
- The maximum step length may have to be reduced if a basic variable otherwise would exceed one of its bounds.
In case 1. CONOPT tries various heuristics to find a more appropriate set of basic variables. If this does not work, some "difficult" equations, i.e. equations with large infeasibilities and significant nonlinearities, are temporarily removed from the model, and Newton's method is applied to the remaining set of "easy" equations.
In case 2. CONOPT will remove the basic variable that first reaches one of its bounds from the basis and replace it by one of the nonbasic variables. Newton's method is then applied to the new set of basic variables. The logic is very close to that of the dual simplex method. In cases where some of the basic variables are exactly at a bound CONOPT uses an anti degeneracy procedure based on Ryan and Osborne (1988) to prevent cycling.
Phase 0 will end when all equations except possibly some "difficult" equations are feasible within some small tolerance. If there are no difficult equations, CONOPT has found a feasible solution and it will proceed with Phase 3 and 4. Otherwise, Phase 1 and 2 is used to make the difficult equations feasible.
The iteration output will during Phase 0 have the following columns in the iteration log: Iter, Phase, Ninf, Infeasibility, Step, MX, and OK. The number in the Ninf column counts the number of "difficult" infeasible equations, and the number in the Infeasibility column shows the sum of the absolute infeasibilities in all the general constraints, both in the easy and in the difficult ones. There are three possible combinations of values in the MX and OK columns: combination (1) has F in the MX column and T in the OK column and it will always be combined with 1.0 in the Step column: this is an ideal Newton step. The infeasibilities in the easy equations should be reduced quickly, but the difficult equations may dominate the number in the Infeasibility column so you may not observe it. However, a few of these iterations is usually enough to terminate Phase 0. Combination (2) has T in the MX column indicating that a basic variable has reached its bound and is removed from the basis as in case 2. above. This will always be combined with T in the OK column. The Step column will show a step length less than the ideal Newton step of 1.0. Combination (3) has F in both the MX and OK column. It is the bad case and will always be combined with a step of 0.0: this is an iteration where nonlinearities are dominating and one of the heuristics from case 1. must be used.
The success of the Phase 0 procedure is based on being able to choose a good basis that will allow a full Newton step. It is therefore important that as many variables as possible have been assigned reasonable initial values so CONOPT has some variables away from their bounds to select from. This topic was discussed in more detail in section Initial Values .
The start and the iterations of Phase 0 can, in addition to the crash option described in section Finding a Feasible Solution: Phase 0 be controlled with the three options lslack, lsmxbs, and lmmxsf described in Appendix B.
Finding a Feasible Solution: Phase 1 and 2
Most of the equations will be feasible when phase 0 stops. To remove the remaining infeasibilities CONOPT uses a procedure similar to the phase 1 procedure used in Linear Programming: artificial variables are added to the infeasible equations (the equations with Large Residuals), and the sum of these artificial variables is minimized subject to the feasible constraints remaining feasible. The artificial variable are already part of the model as slack variables; their bounds are simply relaxed temporarily.
This infeasibility minimization problem is similar to the overall optimization problem: minimize an objective function subject to equality constraints and bounds on the variables. The feasibility problem is therefore solved with the ordinary GRG optimization procedure. As the artificial variables gradually become zero, i.e. as the infeasible equations become feasible, they are taken out of the auxiliary objective function. The number of infeasibilities (shown in the Ninf column of the log file) and the sum of infeasibilities (in the Infeasibility column) will therefore both decrease monotonically.
The iteration output will label these iterations as phase 1 and/or phase 2. The distinction between phases 1 (linear mode) and 2 (nonlinear mode) is similar to the distinction between phases 3 and 4, which are described in the next sections.
Linear and Nonlinear Mode: Phase 1 to 4
The optimization itself follows step 2 to 9 of the GRG algorithm shown in The CONOPT Algorithm above. The factorization in step 3 is performed using an efficient sparse LU factorization similar to the one described by Suhl and Suhl (1990). The matrix operations in step 4 and 5 are also performed sparse.
Step 7, selection of the search direction, has several variants, depending on how nonlinear the model is locally. When the model appears to be fairly linear in the area in which the optimization is performed, i.e. when the function and constraint values are close to their linear approximation for the steps that are taken, then CONOPT takes advantages of the linearity: The derivatives (the Jacobian) are not computed in every iteration, the basis factorization is updated using cheap LP techniques as described by Reid (1982), the search direction is determined without use of second order information, i.e. similar to a steepest descend algorithm, and the initial steplength is estimated as the step length where the first variable reaches a bound; very often, this is the only step length that has to be evaluated. These cheap almost linear iterations are referred to a Linear Mode and they are labeled Phase 1 when the model is infeasible and objective is the sum of infeasibilities and Phase 3 when the model is feasible and the real objective function is optimized.
When the constraints and/or the objective appear to be more nonlinear CONOPT will still follow step 2 to 9 of the GRG algorithm. However, the detailed content of each step is different. In step 2, the Jacobian must be recomputed in each iteration since the nonlinearities imply that the derivatives change. On the other hand, the set of basic variables will often be the same and CONOPT will take advantage of this during the factorization of the basis. In step 7 CONOPT uses the BFGS algorithm to estimate second order information and determine search directions. And in step 8 it will often be necessary to perform more than one step in the line search. These nonlinear iterations are labeled Phase 2 in the output if the solution is still infeasible, and Phase 4 if it is feasible. The iterations in phase 2 and 4 are in general more expensive than the iteration in phase 1 and 3.
Some models will remain in phase 1 (linear mode) until a feasible solution is found and then continue in phase 3 until the optimum is found, even if the model is truly nonlinear. However, most nonlinear models will have some iterations in phase 2 and/or 4 (nonlinear mode). Phase 2 and 4 indicates that the model has significant nonlinear terms around the current point: the objective or the constraints deviate significantly from a linear model for the steps that are taken. To improve the rate of convergence CONOPT tries to estimate second order information in the form of an estimated reduced Hessian using the BFGS formula.
Each iteration is, in addition to the step length shown in column "Step", characterized by two logicals: MX and OK. MX = T means that the step was maximal, i.e. it was determined by a variable reaching a bound. This is the expected value in Phase 1 and 3. MX = F means that no variable reached a bound and the optimal step length will in general be determined by nonlinearities. OK = T means that the line search was well-behaved and an optimal step length was found; OK = F means that the line search was ill-behaved, which means that CONOPT would like to take a larger step, but the feasibility restoring Newton process used during the line search did not converge for large step lengths. Iterations marked with OK = F (and therefore also with MX = F) will usually be expensive, while iterations marked with MX = T and OK = T will be cheap.
Linear Mode: The SLP Procedure
When the model continues to appear linear CONOPT will often take many small steps, each determined by a new variable reaching a bound. Although the line searches are fast in linear mode, each require one or more evaluations of the nonlinear constraints, and the overall cost may become high relative to the progress. In order to avoid the many nonlinear constraint evaluations CONOPT may replace the steepest descend direction in step 7 of the GRG algorithm with a sequential linear programming (SLP) technique to find a search direction that anticipates the bounds on all variables and therefore gives a larger expected change in objective in each line search. The search direction and the last basis from the SLP procedure are used in an ordinary GRG-type line search in which the solution is made feasible at each step. The SLP procedure is only used to generate good directions; the usual feasibility preserving steps in CONOPT are maintained, so CONOPT is still a feasible path method with all its advantages, especially related to reliability.
Iterations in this so-called SLP-mode are identified by numbers in the column labeled InItr in the iteration log. The number in the InItr column is the number of non- degenerate SLP iterations. This number is adjusted dynamically according to the success of the previous iterations and the perceived linearity of the model.
The SLP procedure generates a scaled search direction and the expected step length in the following line search is therefore 1.0. The step length may be less than 1.0 for several reasons:
- The line search is ill-behaved. This is indicated with OK = F and MX = F.
- A basic variable reaches a bound before predicted by the linear model. This is indicated with MX = T and OK = T.
- The objective is nonlinear along the search direction and the optimal step is less than one. This is indicated with OK = T and MX = F.
CONOPT will by default determine if it should use the SLP procedure or not, based on progress information. You may turn it off completely with the line lseslp = f in the CONOPT options file (usually conopt.opt). The default value of lseslp (lseslp = Logical Switch Enabling SLP mode) is t or true, i.e. the SLP procedure is enabled and CONOPT may use it when considered appropriate. It is seldom necessary to define lseslp, but it can be useful if CONOPT repeatedly turns SLP on and off, i.e. if you see a mixture of lines in the iteration log with and without numbers in the InItr column.
Linear Mode: The Steepest Edge Procedure
When optimizing in linear mode (Phase 1 or 3) CONOPT will by default use a steepest descend algorithm to determine the search direction. CONOPT allows you to use a Steepest Edge Algorithm as an alternative. The idea, borrowed from Linear Programming, is to scale the nonbasic variables according to the Euclidean norm of the "updated column" in a standard LP tableau, the so-called edge length. A unit step for a nonbasic variable will give rise to changes in the basic variables proportional to the edge length. A unit step for a nonbasic variable with a large edge length will therefore give large changes in the basic variables which has two adverse effects relative to a unit step for a nonbasic variable with a small edge length: a basic variable is more likely to reach a bound after a very short step length, and the large change in basic variables is more likely to give rise to larger nonlinear terms.
The steepest edge algorithm has been very successful for linear programs, and our initial experience has also shown that it will give fewer iterations for most nonlinear models. However, the cost of maintaining the edge lengths can be more expensive in the nonlinear case and it depends on the model whether steepest edge results in faster overall solution times or not. CONOPT uses the updating methods for the edge lengths from LP, but it must re-initialize the edge lengths more frequently, e.g. when an inversion fails, which happens more frequently in nonlinear models than in linear models, especially in models with many product terms, e.g. blending models, where the rank of the Jacobian can change from point to point.
Steepest edge is turned on with the line, lsanrm = t, in the CONOPT options file (usually conopt.opt). The default value of lsanrm (lsanrm = Logical Switch for A- Norm) is f or false, i.e. the steepest edge procedure is turned off.
The steepest edge procedure is mainly useful during linear mode iterations. However, it has some influence in phase 2 and 4 also: The estimated reduced Hessian in the BFGS method is initialized to a diagonal matrix with elements on the diagonal computed from the edge lengths, instead of the usual scaled unit matrix.
Nonlinear Mode: The SQP Procedure
When progress is determined by nonlinearities CONOPT needs second order information. Some second order information can be derived from the line search and is used in the first iterations in Phase 2 or 4. Depending on progress, CONOPT may switch to a Sequential Quadratic Programming (SQP) procedure that works on a sub-model with linear constraints and a quadratic objective function. The constraints are a linearization of the nonlinear constraints, and the objective function is derived from the Hessian of the Lagrangian function. CONOPT will inside the SQP procedure use exact second order information computed by GAMS. The result of the SQP procedure is a search direction and a basis and CONOPT will afterwards use the same line search procedure and feasibility preserving steps as after the SLP procedure. CONOPT remains a feasible path method with all its advantages, especially related to reliability.
Iterations in this so-called SQP-mode are identified by numbers in the column labeled "InItr" in the iteration log. The number in the InItr column is the number of non-degenerate SQP iterations. The effort spend inside the SQP procedure is adjusted dynamically according to the success of the previous iterations and the reduction in reduced gradient in the quadratic model.
The SQP procedure generates a scaled search direction and the expected step length in the following line search is therefore 1.0. The step length may be less than 1.0 for several reasons:
- The line search is ill-behaved. This is indicated with OK = F and MX = F.
- A basic variable reaches a bound before predicted by the linear model of the constraints. This is indicated with MX = T and OK = T.
- The objective is much more nonlinear along the search direction than expected and the optimal step is not one. This is indicated with OK = T and MX = F.
CONOPT will by default determine if it should use the SQP procedure or not, based on progress information. You may turn it off completely with the line lsesqp = f in the CONOPT options file (usually conopt.opt). The default value of lsesqp (lsesqp = Logical Switch Enabling SQP mode) is t or true, i.e. the SQP procedure is enabled and CONOPT may use it when considered appropriate. It is seldom necessary to define lsesqp, but it can be used for experimentation.
In connection with 1st and 2nd derivatives the listing file (*.lst) will have a few extra lines. The first looks as follows:
The model has 537 variables and 457 constraints with 1597 Jacobian elements, 380 of which are nonlinear. The Hessian of the Lagrangian has 152 elements on the diagonal, 228 elements below the diagonal, and 304 nonlinear variables.
The first two lines repeat information given in the GAMS model statistics and the last two lines describe second order information. CONOPT uses the matrix of second derivatives (the Hessian) of a linear combination of the objective and the constraints (the Lagrangian). The Hessian is symmetric and the statistics show that it has 152 elements on the diagonal and 228 below for a total of 380 elements in this case. This compares favorably to the number of elements in the matrix of first derivatives (the Jacobian).
For some models you may see the following message instead (before the usual CONOPT banner):
** Warning ** Memory Limit for Hessians exceeded. You can use the Conopt option "rvhess"
The creation of the matrix of second derivatives has been interrupted because the matrix became too dense. A dense matrix of second derivatives will be slow to compute and it will need a lot of memory. In addition, it is likely that a dense Hessian will make some of the computations inside the SQP iterations so slow that the potential saving in number of iterations is used up computing and manipulating the Hessian.
CONOPT can use second derivatives even if the Hessian is not available. A special version of the function evaluation routine can compute the Hessian multiplied by a vector (the so-called directional second derivative) without computing the Hessian itself. This routine is used when the Hessian is not available. The directional second derivative approach will require one directional second derivative evaluation call per inner SQP iteration instead of one Hessian evaluation per SQP sub-model.
If you get the "Memory Limit for Hessians exceeded" message you may consider rewriting some equation. Look for nonlinear functions applied to long linear or separable expressions such as log(sum(i,x(i)); as discussed in Section Simple Expressions . An expression like this will create a dense Hessian with card(i) rows and columns. You should consider introducing an intermediate variable that is equal to the long linear or separable expression and then apply the nonlinear function to this single variable. You may also experiment with allocating more memory for the dense Hessian and use it despite the higher cost; it may reduce the number of iterations. This can be done by adding the option rvhess = XX to the CONOPT options file. rvhess is a memory factor with default value 10 so you need a larger value. The value 0.0 is special; it means do not impose a memory limit on the Hessian.
The time spend on the many types of function and derivative evaluations are reported in the listing file in a section like this:
CONOPT time Total 0.734 seconds
of which: Function evaluations 0.031 = 4.3%
1st Derivative evaluations 0.020 = 2.7%
2nd Derivative evaluations 0.113 = 15.4%
Directional 2nd Derivative 0.016 = 2.1%
The function evaluations are computations of the nonlinear terms in the model, and 1st Derivatives evaluations are computations of the Jacobian of the model. 2nd Derivative evaluations are computations of the Hessian of the Lagrangian, and Directional 2nd derivative evaluations are computations of the Hessian multiplied by a vector, computed without computing the Hessian itself. The lines for 2nd derivatives will only be present if CONOPT has used this type of 2nd derivative.
If your model is not likely to benefit from 2nd derivative information or if you know you will run out of memory anyway you can save a small setup cost by telling CONOPT not to generate it using option dohess = f.
How to Select Non-default Options
The non-default options have an influence on different phases of the optimization and you must therefore first observe whether most of the time is spend in Phase 0, Phase 1 and 3, or in Phase 2 and 4.
Phase 0: The quality of Phase 0 depends on the number of iterations and on the number and sum of infeasibilities after Phase 0. The iterations in Phase 0 are much faster than the other iterations, but the overall time spend in Phase 0 may still be rather large. If this is the case, or if the infeasibilities after Phase 0 are large you may try to use the triangular crash options:
lstcrs = t
Observe if the initial sum of infeasibility after iteration 1 has been reduced, and if the number of phase 0 iterations and the number of infeasibilities at the start of phase 1 have been reduced. If lstcrs reduces the initial sum of infeasibilities but the number of iterations still is large you may try:
lslack = t
CONOPT will after the preprocessor immediately add artificial variables to all infeasible constraints so Phase 0 will be eliminated, but the sum and number of infeasibilities at the start of Phase 1 will be larger. You are in reality trading Phase 0 iterations for Phase 1 iterations.
You may also try the experimental bending line search with
lmmxsf = 1
The line search in Phase 0 will with this option be different and the infeasibilities may be reduced faster than with the default lmmxsf = 0. It is likely to be better if the number of iterations with both MX = F and OK~=~F is large. This option may be combined with lstcrs = t. Usually, linear constraints that are feasible will remain feasible. However, you should note that with the bending linesearch linear feasible constraints could become infeasible.
Phase 1 and 3: The number of iterations in Phase 1 and Phase 3 will probably be reduced if you use steepest edge, lsanrm = t, but the overall time may increase. Steepest edge seems to be best for models with less than 5000 constraints, but work in progress tries to push this limit upwards. Try it when the number of iterations is very large, or when many iterations are poorly behaved identified with OK = F in the iteration log. The default SLP mode is usually an advantage, but it is too expensive for a few models. If you observe frequent changes between SLP mode and non-SLP mode, or if many line searches in the SLP iterations are ill-behaved with OK = F, then it may be better to turn SLP off with lseslp = f.
Phase 2 and 4: There are currently not many options available if most of the time is spend in Phase 2 and Phase 4. If the change in objective during the last iterations is very small, you may reduce computer time in return for a slightly worse objective by reducing the optimality tolerance, rtredg.
Miscellaneous Topics
Triangular Models
A triangular model is one in which the non-fixed variables and the equations can be sorted such that the first equation only depends on the first variable, the second equation only depends on the first two variables, and the p-th equation only depends on the first p variables. Provided there are no difficulties with bounds or small pivots, triangular models can be solved one equation at a time using the method describe in section Preprocessing: Pre-triangular Variables and Constraints and the solution process will be very fast and reliable.
Triangular models can in many cases be useful for finding a good initial feasible solution: Fix a subset of the variables so the remaining model is known to be triangular and solve this triangular simulation model. Then reset the bounds on the fixed variables to their original values and solve the original model. The first solve will be very fast and if the fixed variables have been fixed at good values then the solution will also be good. The second solve will start from the good feasible solution generated by the first solve and it will usually optimize much more quickly than from a poor start.
The modeler can instruct CONOPT that a model is supposed to be triangular with the option lstria = t. CONOPT will then use a special version of the preprocessing routine (see section Preprocessing: Pre-triangular Variables and Constraints) that solves the model very efficiently. If the model is solved successfully then CONOPT terminates with the message:
** Feasible solution to a recursive model.
and the Model Status will be 2, Locally Optimal, or 1, Optimal, depending on whether there were any nonlinear pivots or not. All marginals on both variables and equations are returned as 0 (zero) or EPS.
Two SOLVEs with different option files can be arranged by writing the option files as they are needed from within the GAMS program with PUT statements followed by a PutClose. You can also have two different option files, e.g., conopt.opt and conopt.op2, and select the second with the GAMS statement <model>.OptFile = 2;.
The triangular facility handles a number of error situations:
- Non-triangular models: CONOPT will ensure that the model is indeed triangular. If it is not, CONOPT will return model status 5, Locally Infeasible, plus some information that allows the modeler to identify the mistake. The necessary information is related to the order of the variables and equations and number of occurrences of variables and equations, and since GAMS does no have a natural place for this type of information CONOPT returns it in the marginals of the equations and variables. The solution order for the triangular equations and variables that have been solved successfully are defined with positive numbers in the marginals of the equations and variables. For the remaining non- triangular variables and equations CONOPT shows the number of places they appear as negative numbers, i.e. a negative marginal for an equation shows how many of the non- triangular variables that appear in this equation. You must fix one or more variables until at least one of the non-triangular equation only has one non-fixed variable left.
- Infeasibilities due to bounds: If some of the triangular equations cannot be solved with respect to their variable because the variable will exceed the bounds, then CONOPT will flag the equation as infeasible, keep the variable at the bound, and continue the triangular solve. The solution to the triangular model will therefore satisfy all bounds and almost all equations. The termination message will be and the model status will be 5, Locally Infeasible.
** Infeasible solution. xx artificial(s) have been introduced into the recursive equations.
The modeler may in this case add explicit artificial variables with high costs to the infeasible constraints and the resulting point will be an initial feasible point to the overall optimization model. You will often from the mathematics of the model know that only some of the constraints can be infeasible, so you will only need to check whether to add artificials in these equations. Assume that a block of equations matbal(m,t) could become infeasible. Then the artificials that may be needed in this equation can be modeled and identified automatically with the following GAMS constructs:Set aposart(m,t) Add a positive artificial in Matbal anegart(m,t) Add a negative artificial in Matbal; aposart(m,t) = No; anegart(m,t) = No; Positive Variable vposart(m,t) Positive artificial variable in Matbal vnegart(m,t) Negative artificial variable in Matbal; matbal(m,t).. Left hand side =e= right hand side + vposart(m,t)$aposart(m,t) - vnegart(m,t)$anegart(m,t); objDef.. obj =e= other_terms + weight * Sum((m,t), vposart(m,t)$aposart(m,t) +vnegart(m,t)$anegart(m,t) ); Solve triangular model ... aposart(m,t)$(matbal.l(m,t) > matbal.Up(m,t)) = Yes; anegart(m,t)$(matbal.l(m,t) < matbal.Lo(m,t)) = Yes; Solve final model ... - Small pivots: The triangular facility requires the solution of each equation to be locally unique which also means that the pivots used to solve each equation must be nonzero. The model segment will give the message
e1 .. x1 =e= 0; e2 .. x1 * x2 =e= 0;
However, the uniqueness of x2 may not be relevant if the solution just is going to be used as an initial point for a second model. The optionx2 appearing in e2: Pivot too small for triangular model. Value=0.000E+00 ** Infeasible solution. The equations were assumed to be recursive but they are not. A pivot element is too small.lsismp = t(for Logical Switch: Ignore Small Pivots) will allow zero pivots as long as the corresponding equation is feasible for the given initial values.
Constrained Nonlinear System or Square Systems of Equations
There is a special model class in GAMS called CNS - Constrained Nonlinear System. A constrained nonlinear system is a square system of equations, i.e. a model in which the number of non-fixed variables is equal to the number of constraints. Currently, CONOPT and PATH are the only solvers with special treatment for this model class. A CNS model can be solved with a solve statement like
Solve <model> using CNS;
without an objective term. In some cases it may be convenient to solve a CNS model with a standard solve statement combined with an options file that has the statement lssqrs = t. In the latter case, CONOPT will check that the number of non-fixed variables is equal to the number of constraints. In either case, CONOPT will attempt to solve the constraints with respect to the non-fixed variables using Newton's method. The solution process does not include a lot of the safeguards used for ordinary NLP models and when it work it is often very fast and it uses less memory than for the corresponding NLP model. The lack of safeguards means that the solution process just will stop with an error message in some difficult situations and return the current intermediate infeasible solution. Examples of difficulties are that the Jacobian to be inverted is singular, or if one of the non-fixed variables tries to move outside their bounds as described with examples below.
Slacks in inequalities are counted as non-fixed variables which effectively means that inequalities should not be binding. Bounds on the variables are allowed, especially to prevent function evaluation errors for functions that only are defined for some arguments, but the bounds should not be binding in the final solution.
The solution returned to GAMS will in all cases have marginal values equal to 0 or EPS, both for the variables and the constraints.
The termination messages for CNS models are different from the termination messages for optimization models. The message you hope for is
** Feasible solution to a square system.
that usually will be combined with model status 16-Solved. If CONOPT in special cases can guarantee that the solution is unique, for example if the model is linear, then the model status will be 15-Solved Unique.
There are two potential error termination messages related to CNS models. A model with the following two constraints
e1 .. x1 + x2 =e= 1; e2 .. 2*x1 + 2*x2 =e= 2;
will result in the message
** Error in Square System: Pivot too small.
e2: Pivot too small.
x1: Pivot too small.
"Pivot too small" means that the set of constraints is linearly dependent in the current point and there is no unique search direction for Newtons method so CONOPT terminates. The message points to one variable and one constraint. However, this just indicates that the linearly dependent set of constraints and variables include the constraint and variable mentioned. The offending constraint and variable will also be labeled 'DEPND' for linearly dependent in the equation listing. The error will usually be combined with model status 5 - Locally Infeasible. In the cases where CONOPT can guarantee that the infeasibility is not caused by nonlinearities the model status will be 4 - Infeasible. If the constraints are linearly dependent but the current point satisfy the constraints then the solution status will be 17 - Solved Singular, indicating that the point is feasible, but there is probably a whole ray of feasible solution through the current point.
It should be mentioned that the linear dependency and small pivot could be caused by the initial point and that the model could have a solution. An example is
e1.. x1*x2 =E= 1; e2.. x1+x2 =E= 3; x1.l = 1; x2.l = 1;
A model with these two constraints and the bound
e1 .. x1 + x2 =e= 2; e2 .. x1 - x2 =e= 0; x1.lo = 1.5;
will result in the message
** Error in Square System: A variable tries to exceed its bound.
x1: The variable tries to exceed its bound.
because the solution, (x1,x2) = (1,1) violates the bound on x1. This error case will also be combined with model status 5-Locally Infeasible. In the cases where CONOPT can guarantee that the infeasibility is not caused by nonlinearities the model status will be 4 - Infeasible. If you encounter problems with active bounds but you think it is caused by nonlinearities and that there is a solution, then you may try to use the bending linesearch with option lmmxsf = t.
The CNS facility can be used to generate an initial feasible solution in almost the same way as the triangular model facility: Fix a subset of the variables so the remaining model is uniquely solvable, solve this model with the CNS solver or with lssqrs = t, reset the bounds on the fixed variables, and solve the original model. The CNS facility can be used on a larger class of models that include simultaneous sets of equations. However, the square system must be non-singular and feasible; CONOPT cannot, like in the triangular case, add artificial variables to some of the constraints and solve the remaining system when a variable reaches one of its bounds.
Additional information on CNS can be found in the GAMS User's Guide.
Loss of Feasibility
During the optimization you may sometimes see a phase 0 iteration and in rare cases you will see the message "Loss of Feasibility - Return to Phase 0". The background for this is as follows:
To work efficiently, CONOPT uses dynamic tolerances for feasibility and during the initial part of the optimization where the objective changes rapidly fairly large infeasibilities may be acceptable. As the change in objective in each iteration becomes smaller it will be necessary to solve the constraints more accurately so the "noise" in objective value from the inaccurate constraints will remain smaller than the real change. The noise is measured as the scalar product of the constraint residuals with the constraint marginals.
Sometimes it is necessary to revise the accuracy of the solution, for example because the algorithmic progress has slowed down or because the marginal of an inaccurate constraint has grown significantly after a basis change, e.g. when an inequality becomes binding. In these cases CONOPT will tighten the feasibility tolerance and perform one or more Newton iterations on the basic variables. This will usually be very quick and it happens silently. However, Newton's method may fail, for example in cases where the model is degenerate and Newton tries to move a basic variable outside a bound. In this case CONOPT uses some special iteration similar to those discussed in section Finding a Feasible Solution: Phase 0 and they are labeled Phase 0.
These Phase 0 iterations may not converge, for example if the degeneracy is significant, if the model is very nonlinear locally, if the model has many product terms involving variables at zero, or if the model is poorly scaled and some constraints contain very large terms. If the iterations do not converge, CONOPT will issue the "Loss of feasibility ..." message, return to the real Phase 0 procedure, find a feasible solution with the smaller tolerance, and resume the optimization.
In rare cases you will see that CONOPT cannot find a feasible solution after the tolerances have been reduced, even though it has declared the model feasible at an earlier stage. We are working on reducing this problem. Until a final solution has been implemented you are encouraged to (1) consider if bounds on some degenerate variables can be removed, (2) look at scaling of constraints with large terms, and (3) experiment with the two feasibility tolerances, rtnwma and rtnwmi (see Appendix B), if this happens with your model.
Stalling
CONOPT will usually make steady progress towards the final solution. A degeneracy breaking strategy and the monotonicity of the objective function in other iterations should ensure that CONOPT cannot cycle. Unfortunately, there are a few places in the code where the objective function may move in the wrong direction and CONOPT may in fact cycle or move very slowly.
The objective value used to compare two points, in the following called the adjusted objective value, is computed as the true objective plus a noise adjustment term equal to the scalar product of the residuals with the marginals (see section Loss of Feasibility where this noise term also is used). The noise adjustment term is very useful in allowing CONOPT to work smoothly with fairly inaccurate intermediate solutions. However, there is a disadvantage: the noise adjustment term can change even though the point itself does not change, namely when the marginals change in connection with a basis change. The adjusted objective is therefore not always monotone. When CONOPT looses feasibility and returns to Phase 0 there is an even larger chance of non-monotone behavior.
To avoid infinite loops and to allow the modeler to stop in cases with very slow progress CONOPT has an anti-stalling option. An iteration is counted as a stalled iteration if it is not degenerate and (1) the adjusted objective is worse than the best adjusted objective seen so far, or (2) the step length was zero without being degenerate (see OK = F in section Linear and Nonlinear Mode: Phase 1 to 4). CONOPT will stop if the number of consecutive stalled iterations (again not counting degenerate iterations) exceeds lfstal and lfstal is positive. The default value of lfstal is 100. The message will be:
** Feasible solution. The tolerances are minimal and
there is no change in objective although the reduced
gradient is greater than the tolerance.
Large models with very flat optima can sometimes be stopped prematurely due to stalling. If it is important to find a local optimum fairly accurately then you may have to increase the value of lfstal.
Overflow and NaN (Not A Number)
Very large values or overflow can appear in a number of places. CONOPT cannot use these values in the optimization since the results would be unreliable or useless. CONOPT is therefore trying to detect these values and take appropriate action.
Even though most modern computers can work with numbers from 1.e-300 to 1.e+300 CONOPT considers all numbers that are larger than 1.e40 or NaN to be 'bad' and useles. NaN means Not A Number and includes Infinity and Real Overflow.
Bad numbers can have two sources. They can come from the modeler expressions or they can be generated internally in CONOPT. The nonlinear constraints or the derivatives of these constraints may return very large values. If a constraint returns a bad number you will see a message like
** A function value is very large or NaN (Not a Number).
Add bound to ensure that the function values are defined and bounded.
and if a derivatives returns a bad number the message will be something like
** A derivative is very large or NaN (Not a Number).
Add bound to ensure that the derivatives are defined and bounded.
The modeler must in both cases adjust the model to prevent that CONOPT receives these bad numbers so CONOPT stops immediately.
Bad numbers can also in rare cases appear as a result of computations inside CONOPT. Since all primal variables and all derivatives are bounded the bad numbers can only appear as a result of operations involving the factorization of the basis matrix, including the dual variables. You will in this case see a message like
** Overflow or Nan (Not A Number) has been encountered indicating
numerical difficulties. Trying to repair by increasing the
absolute and relative pivot tolerances (Rtpiva and Rvpivr)
and allowing small values to be scaled up by decreasing
the minimum scale factor, Rtmins.
Since the source of the problem is the factorization of the basis CONOPT will adjust the tolerances that are used while computing this factorization. Essentially, we must avoid very small pivots and the pivoting tolerances are therefore increased. The source of very small pivots can also be constraints were all terms are very small so CONOPT will also change the minimum scaling factor to try to avoid this source. CONOPT will continue the optimization after changing the tolerances and if the problem appears again if will change the tolerances even more, but since there is a limit to how much they can be adjusted CONOPT may have to give up and it will happen with this message
** Overflow or Nan (Not A Number) continues to be encountered
after multiple attempt to repair by changed tolerances.
CONOPT will give up.
The termination message will in this case be
** Feasible solution. The solution process has been terminated
because intermediate results have become NaN (Not A Number).
or
** Feasible solution. The solution process has been terminated
because intermediate results have become NaN (Not A Number).
If you encounter messages with NaN it is always a problem with scaling or structure. The most likely source is constraints with only small terms. Try to avoid them by scaling the variables and constraints appropriately, or try to use option rtmins. Or make CONOPT ignore these constraints by using a larger absolute pivot tolerance, rtpiva.
Another source are structured models with long chains of relationships. These models will usually have lags or leads and neighboring variables are related with a factor different from one, i.e.
dyn(i).. x(i) =e= x(i-1)*1.5 + u(i);
or
dif(i).. 2*x(i) =e= x(i-1) + x(i+1) + u(i);
CONOPT will try to solve the constraints in the proper order to avoid exploding variables, but a larger relative pivot tolerance, rtpivr, may also help. If you have a dynamic model and the variables are supposed to grow rapidly over time then you may consider having a scale factor that also grows with time.
External Equations and Extrinsic Functions
CONOPT can be used with external equations and extrinsic functions written in a programming language such as Fortran or C. Additional information is available in the GAMS User's Guide External Equations and Extrinsic Functions.
Extrinsic functions can be debugged using the function suffixes gradn and hessn which use finite differences to approximate the gradient and Hessian using multiple function calls. For details check model derivtst in the GAMS Model Library. If external equations are present CONOPT will automatically turn the Function and Derivative Debugger on in the initial point to discover potential errors in the gradient calculation inside the external library. The debugger will not only check the gradients of the external library but even check the gradients calculated by GAMS. In rare cases the debugger may report problems in the regular algebra part of the model for which GAMS has calculated the gradients. These violates should be small and can be ignored. After verifying that the external part of the model has been programmed correctly you may turn debugging off again by setting Lkdebg to 0 in an options file.
The debugger has two types of check. The first type ensures that the external equations do not depend on other variables than the ones you have specified in the GAMS representation. Structural errors found by these check are usually caused by programming mistakes and must be corrected. The second type of check verifies that the derivatives returned by the external equations and extrinsic functions are consistent with the rate of change in function values. A derivative is considered to be wrong if the value returned by the modeler deviates from the value computed using numerical differences by more than rtmxj2 times the step used for the numerical difference (usually around 1.e-7). This check is correct if second derivatives are less than rtmxj2. rtmxj2 has a default value of 1.e4. If your model has larger second derivatives you may increase it in order not to get wrong error messages.
The number of error messages from the Function and Derivative Debugger is limited by lfderr with a default value of 10.
See Debugging options for a list of options that control the debugger.
APPENDIX B - Options
The options that ordinary GAMS users can access are listed below. Options starting on R assume real values, options starting on LS assume logical values (TRUE, T, 1, or FALSE, F, or 0), and all other CR-Cells starting on L assume integer values. The logical option dohess is only used by the interface between GAMS and CONOPT.
Algorithmic options
| Option | Description | Default |
|---|---|---|
| LF2DRV | Limit on errors in Directional Second Derivative evaluation. | 10 |
| LFDEGI | Limit on number of degenerate iterations before starting degeneracy breaking strategy. | 10 |
| LFEERR | Limit on number of function evaluation errors. Overwrites GAMS Domlim option | GAMS DomLim |
| LFHSOK | Limit on errors in Hessian evaluation. | 10 |
| LFITER | Maximum number of iterations. Overwrites GAMS Iterlim option. | GAMS IterLim |
| LFMXNS | Maximum number of new superbasic variables added in one iteration. | auto |
| LFNICR | Limit on number of iterations with slow progress (relative less than Rtobjl). | 20 |
| LFNSUP | Maximum number of superbasic variables in the approximation to the Reduced Hessian. | auto |
| LFSCAL | Rescaling frequency. | 5 |
| LFSTAL | Limit on the number of stalled iterations. | 100 |
| LFUSDF | Limit on the number of candidates for defined variable in one constraint | 2 |
| LMDEBG | Method used by the function and derivative debugger. | 0 |
| LMMXSF | Method used to determine the step in Phase 0. | 0 |
| LMMXST | Method used to determine the maximum step while tightening tolerances. | 0 |
| LMNDIA | Method for initializing the diagonal of the approximate Reduced Hessian | 0 |
| LMSCAL | Method used for scaling. | 3 |
| LMUSDF | Method used with defined variables | 0 |
| LS2NDI | Flag for approximating Hessian information for incoming superbasics. | 0 |
| LS2PTJ | Flag for use of perturbations to compute 2nd derivatives in SQP method. | 1 |
| LSANRM | Flag for turning Steepest Edge on. | 0 |
| LSCRSH | Flag for crashing an initial basis without fixed slacks | 1 |
| LSESLP | Flag for enabling SLP mode. | 1 |
| LSESQP | Flag for enabling of SQP mode. | 1 |
| LSISMP | Flag for Ignoring Small Pivots in Triangular models | 0 |
| LSLACK | Flag for selecting initial basis as Crash-triangular variables plus slacks. | 0 |
| LSPOST | Pre-processor flag for identifying and using post-triangular equations. | 1 |
| LSPRET | Pre-processor flag for identifying and using pre-triangular equations. | 1 |
| LSSCAL | Flag for dynamic scaling. | 1 |
| LSSQRS | Flag for Square System. Alternative to defining modeltype=CNS in GAMS | 0 |
| LSTCRS | Flag for using the triangular crash method. | 0 |
| LSTRIA | Flag for triangular or recursive system of equations. | 0 |
| LSTRID | Flag for turning diagnostics on for the post-triangular equations. | 0 |
| LSUQDF | Flag for requiring defined variables to be unique | 1 |
| LSUSDF | Flag for forcing defined variables into the basis | 1 |
| PRDEF | Flag for printing the defined variables and their defining constraints. | 0 |
| PRPOST | Flag for printing the post-triangular part of the model | 0 |
| PRPREC | Flag for printing the variables changed by the pre-processor | 0 |
| PRPRET | Flag for printing the pre-triangular part of the model | 0 |
| RTBND1 | Bound filter tolerance for solution values close to a bound. | 1.e-7 |
| RTBNDT | Bound tolerance for defining variables as fixed. | 1.e-7 |
| RTIPVA | Absolute Pivot Tolerance for building initial basis. | 1.e-7 |
| RTIPVR | Relative Pivot Tolerance for building initial basis | 1.e-3 |
| RTMAXJ | Upper bound on the value of a function value or Jacobian element. | 1.e10 |
| RTMAXS | Upper bound on scale factors. | 1.e9 |
| RTMAXV | Upper bound on solution values and equation activity levels | 1.e10 |
| RTMINA | Zero filter for Jacobian elements and inversion results. | 1.e-20 |
| RTMINJ | Filter for small Jacobian elements to be ignored during scaling. | 1.e-5 |
| RTMINS | Lower bound for scale factors computed from values and 1st derivatives. | 1 |
| RTMNS2 | Lower bound for scale factors based on large 2nd derivatives. | 1.e-6 |
| RTNWMA | Maximum feasibility tolerance (after scaling). | 1.e-7 |
| RTNWMI | Minimum feasibility tolerance (after scaling). | 4.e-10 |
| RTNWTR | Feasibility tolerance for triangular equations. | 2.0e-8 |
| RTOBJL | Limit for relative change in objective for well-behaved iterations. | 3.0e-12 |
| RTOBJR | Relative accuracy of the objective function. | 3.0e-13 |
| RTONED | Accuracy of One-dimensional search. | 0.2 |
| RTPIVA | Absolute pivot tolerance. | 1.e-10 |
| RTPIVR | Relative pivot tolerance during basis factorizations. | 0.05 |
| RTPIVT | Absolute pivot tolerance for nonlinear elements in pre-triangular equations. | 1.e-5 |
| RTPIVU | Relative pivot tolerance during basis updates. | 0.05 |
| RTPREC | Tolerance for printing variables changed by the pre-processor | 0.0 |
| RTPREL | Tolerance for defining large changes in variables in pre-processor | 0.01 |
| RTREDG | Optimality tolerance for reduced gradient. | 1.e-7 |
| RVFILL | Fill in factor for basis factorization. | 5 |
| RVTIME | Time Limit. Overwrites the GAMS Reslim option. | GAMS ResLim |
Debugging options
| Option | Description | Default |
|---|---|---|
| LFDERR | Limit on number of error messages from function and derivative debugger. | 10 |
| LKDEBG | Flag for debugging of first derivatives | 0 |
| RTMXJ2 | Upper bound on second order terms. | 1.e4 |
| RTZERN | Zero-Noise in external equations | 0.0 |
Output options
| Option | Description | Default |
|---|---|---|
| LFEMSG | Limit on number of error messages related to large function value and Jacobian elements. | 10 |
| LFILOG | Frequency for log-lines for non-SLP/SQP iterations. | auto |
| LFILOS | Frequency for log-lines for SLP or SQP iterations. | auto |
| LFTMSG | Limit on number of error messages related to infeasible pre-triangle. | 25 |
Interface options
| Option | Description | Default |
|---|---|---|
| cooptfile | ||
| DO2DIR | Flag for computing and using directional 2nd derivatives. | auto |
| DOHESS | Flag for computing and using 2nd derivatives as Hessian of Lagrangian. | auto |
| heaplimit | Maximum Heap size in MB allowed | Infinite |
| pretri2log | Send messages about the pre-triangular analyser to the log | 0 |
| RVHESS | Memory factor for Hessian generation: Skip if #Hessian elements > #Jacobian elements*Rvhess, 0 means unlimited. | 10 |
cooptfile (string): ↵
DO2DIR (boolean): Flag for computing and using directional 2nd derivatives. ↵
If turned on, make directional second derivatives (Hessian matrix times directional vector) available to CONOPT. The default is on, but it will be turned off of the model has external equations (defined with =X=) and the user has not provided directional second derivatives. If both the Hessian of the Lagrangian (see DOHESS) and directional second derivatives are available then CONOPT will use both: directional second derivatives are used when the expected number of iterations in the SQP sub-solver is low and the Hessian is used when the expected number of iterations is large.
Default:
auto
DOHESS (boolean): Flag for computing and using 2nd derivatives as Hessian of Lagrangian. ↵
If turned on, compute the structure of the Hessian of the Lagrangian and make it available to CONOPT. The default is usually on, but it will be turned off if the model has external equations (defined with =X=) or if the Hessian becomes too dense. See also DO2DIR and RVHESS.
Default:
auto
heaplimit (real): Maximum Heap size in MB allowed ↵
Default:
Infinite
LF2DRV (integer): Limit on errors in Directional Second Derivative evaluation. ↵
If the evaluation of Directional Second Derivatives (Hessian information in a particular direction) has failed more than Lf2drv times CONOPT will not attempt to evaluate them any more and will switch to methods that do not use Directional Second Derivatives. Note that second order information may not be defined even if function and derivative values are well-defined, e.g. in an expression like power(x,1.5) at x=0.
Default:
10
LFDEGI (integer): Limit on number of degenerate iterations before starting degeneracy breaking strategy. ↵
The default CONOPT pivoting strategy has focus on numerical stability, but it can potentially cycle. When the number of consecutive degenerate iterations exceeds LFDEGI CONOPT will switch to a pivoting strategy that is guaranteed to break degeneracy but with slightly weaker numerical properties.
Default:
10
LFDERR (integer): Limit on number of error messages from function and derivative debugger. ↵
The function and derivative debugger (see LKDEBG) may find a very large number of errors, all derived from the same source. To avoid very large amounts of output CONOPT will stop the debugger after LFDERR error have been found.
Range: {
1, ..., ∞}Default:
10
LFEERR (integer): Limit on number of function evaluation errors. Overwrites GAMS Domlim option ↵
Synonym: domlim
Function values and their derivatives are assumed to be defined in all points that satisfy the bounds of the model. If the function value or a derivative is not defined in a point CONOPT will try to recover by going back to a previous safe point (if one exists), but it will not do it more than at most Lfeerr times. If CONOPT is stopped by functions or derivatives not being defined it will return with a intermediate infeasible or intermediate non-optimal model status.
Default:
GAMS DomLim
LFEMSG (integer): Limit on number of error messages related to large function value and Jacobian elements. ↵
Very large function value or derivatives (Jacobian elements) in a model will lead to numerical difficulties and most likely to inaccurate primal and/or dual solutions. CONOPT is therefore imposing an upper bound on the value of all function value and derivatives. This bound is 1.e30 for scaled models and RTMAXJ for unscaled models. If the bound is violated CONOPT will return with an intermediate infeasible or intermediate non-optimal solution and it will issue error messages for all the violating function value and Jacobian elements, up to a limit of Lfemsg error messages.
Range: {
1, ..., ∞}Default:
10
LFHSOK (integer): Limit on errors in Hessian evaluation. ↵
If the evaluation of Hessian information has failed more than Lfhsok times CONOPT will not attempt to evaluate it any more and will switch to methods that do not use the Hessian. Note that second order information may not be defined even if function and derivative values are well-defined, e.g. in an expression like power(x,1.5) at x=0.
Default:
10
LFILOG (integer): Frequency for log-lines for non-SLP/SQP iterations. ↵
Lfilog and Lfilos can be used to control the amount of iteration send to the log file. The non-SLP/SQP iterations, i.e. iterations in phase 0, 1, and 3, are usually fast and writing a log line for each iteration may be too much, especially for smaller models. The default value for the log frequency for these iterations is therefore set to 10 for small models, 5 for models with more than 500 constraints or 1000 variables and 1 for models with more than 2000 constraints or 3000 variables.
Range: {
1, ..., ∞}Default:
auto
LFILOS (integer): Frequency for log-lines for SLP or SQP iterations. ↵
Lfilog and Lfilos can be used to control the amount of iteration send to the log file. Iterations using the SLP and/or SQP sub-solver, i.e. iterations in phase 2 and 4, may involve several inner iterations and the work per iteration is therefore larger than for the non-SLP/SQP iterations and it may be relevant to write log lines more frequently. The default value for the log frequency is therefore 5 for small models and 1 for models with more than 500 constraints or 1000 variables.
Range: {
1, ..., ∞}Default:
auto
LFITER (integer): Maximum number of iterations. Overwrites GAMS Iterlim option. ↵
Synonym: iterlim
The iteration limit can be used to prevent models from spending too many resources. You should note that the cost of the different types of CONOPT iterations (phase 0 to 4) can be very different so the time limit (GAMS Reslim or option RVTIME) is often a better stopping criterion. However, the iteration limit is better for reproducing solution behavior across machines.
Default:
GAMS IterLim
LFMXNS (integer): Maximum number of new superbasic variables added in one iteration. ↵
When there has been a sufficient reduction in the reduced gradient in one subspace new non-basics can be selected to enter the superbasis. The ones with largest reduced gradient of proper sign are selected, up to a limit. If Lfmxns is positive then the limit is min(500,Lfmxns). If Lfmxns is zero (the default) then the limit is selected dynamically by CONOPT depending on model characteristics.
Default:
auto
LFNICR (integer): Limit on number of iterations with slow progress (relative less than Rtobjl). ↵
The optimization is stopped if the relative change in objective is less than RTOBJL for Lfnicr consecutive well-behaved iterations.
Range: {
2, ..., ∞}Default:
20
LFNSUP (integer): Maximum number of superbasic variables in the approximation to the Reduced Hessian. ↵
CONOPT uses and stores a dense lower-triangular matrix as an approximation to the Reduced Hessian. The rows and columns correspond to the superbasic variable. This matrix can use a large amount of memory and computations involving the matrix can be time consuming so CONOPT imposes a limit on on the size. The limit is LFNSUP if LFNSUP is defined by the modeler and otherwise a value determined from the overall size of the model. If the number of superbasics exceeds the limit, CONOPT will switch to a method based on a combination of SQP and Conjugate Gradient iterations assuming some kind of second order information is available. If no second order information is available CONOPT will use a quasi-Newton method on a subset of the superbasic variables and rotate the subset as the reduced gradient becomes small.
Range: {
5, ..., ∞}Default:
auto
LFSCAL (integer): Rescaling frequency. ↵
The row and column scales are recalculated at least every Lfscal new point (degenerate iterations do not count), or more frequently if conditions require it.
Range: {
1, ..., ∞}Default:
5
LFSTAL (integer): Limit on the number of stalled iterations. ↵
An iteration is considered a stalled iteration it there is no change in objective because the linesearch is limited by nonlinearities or numerical difficulties. Stalled iterations will have Step = 0 and F in the OK column of the log file. After a stalled iteration CONOPT will usually try various heuristics to get a better basis and a better search direction. However, the heuristics may not work as intended or they may even return to the original bad basis, so to prevent cycling CONOPT stops after Lfstal stalled iterations and returns an Intermediate Infeasible or Intermediate Nonoptimal solution.
Range: {
2, ..., ∞}Default:
100
LFTMSG (integer): Limit on number of error messages related to infeasible pre-triangle. ↵
If the pre-processor determines that the model is infeasible it tries to define a minimal set of variables and constraints that define the infeasibility. If this set is larger than LFTMSG elements the report is considered difficult to use and it is skipped.
Default:
25
LFUSDF (integer): Limit on the number of candidates for defined variable in one constraint ↵
When there are more than one candidate to be selected as a defined variable in a constraint CONOPT tries to select the most appropriate in order to select as many defined variables as possible. However, to avoid too much arbitrariness this is only attempted if there are not more than Lfusdf candidates.
Default:
2
LKDEBG (integer): Flag for debugging of first derivatives ↵
Lkdebg controls how often the derivatives are tested. Debugging of derivatives is only relevant for user-written functions in external equations defined with =X=. The amount of debugging is controlled by LMDEBG. See RTMXJ2 for a definition of when derivatives are considered wrong.
Default:
0
value meaning -1The derivatives are tested in the initial point only. 0No debugging +nThe derivatives are tested in all iterations that can be divided by Lkdebg, provided the derivatives are computed in this iteration. (During phase 0, 1, and 3 derivatives are only computed when it appears to be necessary.)
LMDEBG (integer): Method used by the function and derivative debugger. ↵
The function and derivative debugger (turned on with LKDEBG) can perform a fairly cheap test or a more extensive test, controlled by LMDEBG. See RTMXJ2 for a definition of when derivatives are considered wrong. All tests are performed in the current point found by the optimization algorithm.
Default:
0
value meaning 0Perform tests for sparsity pattern and tests that the numerical values of the derivatives appear to be correct. This is the default. 1As 0 plus make extensive test to determine if the functions and their derivatives are continuous around the current point. These tests are much more expensive and should only be used of the cheap test does not find an error but one is expected to exist.
LMMXSF (integer): Method used to determine the step in Phase 0. ↵
The steplength used by the Newton process in phase 0 is computed by one of two alternative methods controlled by LMMXSF:
Default:
0
value meaning 0The standard ratio test method known from the Simplex method. CONOPT adds small perturbations to the bounds to avoid very small pivots and improve numerical stability. Linear constraints that initially are feasible will remain feasible with this default method. 1A method based on bending (projecting the target values of the basic variables on the bounds) until the sum of infeasibilities is close to its minimum. Linear constraints that initially are feasible may become infeasible due to bending. The method does not use anti-degeneracy. This will to be taken care off by removing difficult constraints from the Newton Process at regular intervals. The bending method can sometimes be useful for CNS models that stop when a variable exceeds its bound in an intermediate point even though the final solution is known to be inside the bounds.
LMMXST (integer): Method used to determine the maximum step while tightening tolerances. ↵
The steplength used by the Newton process when tightening tolerances is computed by one of two alternative methods controlled by LMMXST:
Default:
0
value meaning 0The standard ratio test method known from the Simplex method. CONOPT adds small perturbations to the bounds to avoid very small pivots and improve numerical stability. Linear constraints that initially are feasible will remain feasible with this default method. 1A method based on bending (projecting the target value of the basic variables on the bounds) until the sum of infeasibilities is close to its minimum.
LMNDIA (integer): Method for initializing the diagonal of the approximate Reduced Hessian ↵
Each time a nonbasic variable is made superbasic a new row and column is added to the approximate Reduced Hessian. The off-diagonal elements are set to zero and the diagonal to a value controlled by LMNDIA:
Default:
0
value meaning 0The new diagonal element is set to the geometric mean of the existing diagonal elements. This gives the new diagonal element an intermediate value and new superbasic variables are therefore not given any special treatment. The initial steps should be of good size, but build-up of second order information in the new sub-space may be slower. The larger diagonal element may also in bad cases cause premature convergence. 1The new diagonal elements is set to the minimum of the existing diagonal elements. This makes the new diagonal element small and the importance of the new superbasic variable will therefore be high. The initial steps can be rather small, but better second order information in the new sub-space should be build up faster.
LMSCAL (integer): Method used for scaling. ↵
CONOPT will by default use scaling of the equations and variables of the model to improve the numerical behavior of the solution algorithm and the accuracy of the final solution, see LSSCAL and LMSCAL. The objective of the scaling process is to reduce the values of all large primal and dual variables as well as the values of all large first derivatives so they become closer to 1. Small values are usually not scaled up, see RTMAXS and RTMINS. Scaling method 3 is recommended. The others are only kept for backward compatibility.
Default:
3
value meaning 0Scaling is based on repeatedly dividing the rows and columns by the geometric means of the largest and smallest elements in each row and column. Very small elements less than RTMINJ are considered equal to RTMINJ. 1Similar to 3 below, but the projection on the interval [Rtmins,Rtmaxs] is applied at a different stage. With method 1, abs(X)*abs(Jac) with small X and very large Jac is scaled very aggressively with a factor abs(Jac). With method 3, the scale factor is abs(X)*abs(Jac). The difference is seen in models with terms like Sqrt(X) close to X = 0. 2As 1 but the terms are computed based on a moving average of the squares X and Jac. The purpose of the moving average is to keep the scale factor more stable. This is often an advantage, but for models with very large terms (large variables and in particular large derivatives) in the initial point the averaging process may not have enough time to bring the scale factors into the right region. 3Rows are first scaled by dividing by the largest term in the row, then columns are scaled by dividing by by the maximum of the largest term and the value of the variable. A term is here defined as abs(X)*abs(Jac) where X is the value of the variable and Jac is the value of the derivative (Jacobian element). The scale factors are then projected on the interval between Rtmins and Rtmaxs.
LMUSDF (integer): Method used with defined variables ↵
When defined variables are identified (see LSUSDF) they can be used in two ways, controlled by LMUSDF:
Default:
0
value meaning 0Defined variables are only used in the initial point and for the initial basis (default). 1Defined variables are kept basic and the defining constraints are used to recursively assign values to the defined variables in all trial points.
LS2NDI (boolean): Flag for approximating Hessian information for incoming superbasics. ↵
If Ls2ndi is turned on (1) CONOPT will try to estimate second order Hessian information for incoming superbasic variables based on directional second derivatives. This is more costly than the standard method described under LMNDIA.
Default:
0
LS2PTJ (boolean): Flag for use of perturbations to compute 2nd derivatives in SQP method. ↵
If on (1) CONOPT may use perturbations of the Jacobian to compute directional 2nd derivatives if they are not provided with other cheaper and more accorate methods. With GAMS it is only relevant for models with functions defined in external function libraries or models with external equations defined with the =X= equation type.
Default:
1
LSANRM (boolean): Flag for turning Steepest Edge on. ↵
Flag used to turn steepest edge pricing on (1) or off (0). Steepest edge pricing makes the individual iterations more expensive but it may decrease their number. Only experimentation can show if it is worth while.
Default:
0
LSCRSH (boolean): Flag for crashing an initial basis without fixed slacks ↵
When turned on (1) CONOPT will try to crash a basis without fixed slacks in the basis. Fixed slacks are only included in a last round to fill linearly dependent rows. When turned off, large infeasible slacks will be included in the initial basis with preference for variables and slacks far from bound.
Default:
1
LSESLP (boolean): Flag for enabling SLP mode. ↵
If Lseslp is on (the default) then the SLP (sequential linear programming) sub-solver can be used, otherwise it is turned off.
Default:
1
LSESQP (boolean): Flag for enabling of SQP mode. ↵
If Lsesqp is on (the default) then the SQP (sequential quadratic programming) sub-solver can be used, otherwise it is turned off.
Default:
1
LSISMP (boolean): Flag for Ignoring Small Pivots in Triangular models ↵
Ignore SMall Pivots. When turned on CONOPT will ignore the non-uniqueness from small pivots during a triangular solve (see LSTRIA). Note, that the non-uniqueness may propagate to later equations, but we cannot check for it in nonlinear equations.
Default:
0
LSLACK (boolean): Flag for selecting initial basis as Crash-triangular variables plus slacks. ↵
When turned on together with LSTCRS CONOPT will use the triangular crash procedure and select the initial basis as the crash-triangular variables plus slacks in all remaining rows.
Default:
0
LSPOST (boolean): Pre-processor flag for identifying and using post-triangular equations. ↵
When turned on (the default) CONOPT will try to identify post-triangular equations. Otherwise this phase is ignored.
Default:
1
LSPRET (boolean): Pre-processor flag for identifying and using pre-triangular equations. ↵
When turned on (the default) CONOPT will try to identify pre-triangular equations. Otherwise this phase is ignored.
Default:
1
LSSCAL (boolean): Flag for dynamic scaling. ↵
When Lsscal is on (the default) CONOPT will use dynamic scaling of equations and variables. See also LMSCAL.
Default:
1
LSSQRS (boolean): Flag for Square System. Alternative to defining modeltype=CNS in GAMS ↵
When turned on the modeler declares that this is a square system, i.e. the number of non-fixed variables must be equal to the number of constraints, no bounds must be active in the final solution, and the basis selected from the non-fixed variables must always be nonsingular.
Default:
0
LSTCRS (boolean): Flag for using the triangular crash method. ↵
When turned on CONOPT will try to crash a triangular basis using ideas by Gould and Reid. The procedure relies on identifying and using good initial values provided by the modeler and only assigning values to variables that are not initialized. Should only be used when several important variables have been given reasonable initial values. The sum of infeasibilities may for some models grow during the crash procedure, so modelers are advised that the option should be used with caution. The option will be ignored if defined variables are forced into the bases Lsusdf.
Default:
0
LSTRIA (boolean): Flag for triangular or recursive system of equations. ↵
If turned on the equations must form a recursive system. Equations that depend on known variables are allowed as long as they are consistent, e.g. x = 1 and 2*x = 2. If the equations are not recursive the model is considered infeasible, and the equations with minimum row count are flagged together with the columns they intersect. See also LSISMP.
Default:
0
LSTRID (boolean): Flag for turning diagnostics on for the post-triangular equations. ↵
If turned on certain diagnostic messages related to the post-triangular equations will be printed. The messages are mainly related to unusual modeling constructs where linear variables for example only appear in the objective or where certain constraints are guarantied redundant.
Default:
0
LSUQDF (boolean): Flag for requiring defined variables to be unique ↵
When turned on (1) CONOPT will not allow defined variables unless they are unique. We exclude a variable if it can be defined from more than one equation, and we exclude equations if they can be used to define more than one variable.
Default:
1
LSUSDF (boolean): Flag for forcing defined variables into the basis ↵
When turned on (1) CONOPT will identify defined variables from constraints of the type x(i) = f(x) where x(i) is free or implied free. The largest number of defined variables possible will be made basic and will be assigned initial values that are consistent with their defining constraint. When turned off (0) defined variables and their defining constraints are treated like all other variables and constraints. When turned on the triangular crash (LSTCRS) will not be used
Default:
1
PRDEF (boolean): Flag for printing the defined variables and their defining constraints. ↵
When turned on (1) CONOPT will print a list of the defined variables and their defining constraints in the order in which they can be evaluated.
Default:
0
pretri2log (boolean): Send messages about the pre-triangular analyser to the log ↵
Default:
0
PRPOST (boolean): Flag for printing the post-triangular part of the model ↵
When turned on (1) CONOPT will print a list of the post-triangular constraints and the variables they are solved for in the order in which they can be evaluated.
Default:
0
PRPREC (boolean): Flag for printing the variables changed by the pre-processor ↵
When turned on (1) CONOPT will print a list of the variables that are changed by the pre-processor. The list includes pre-triangular variables, variables changed by implied bounds, and definitional variables. The three lists can for some models be very long and you can limit the list to variables that are changed by more than (RTPREC)
Default:
0
PRPRET (boolean): Flag for printing the pre-triangular part of the model ↵
When turned on (1) CONOPT will print a list of the pre-triangular constraints and the variables they are solved for, including the solution values, in the order in which they are solved.
Default:
0
RTBND1 (real): Bound filter tolerance for solution values close to a bound. ↵
A variable is considered to be at a bound if its distance from the bound is less than Rtbnd1 Max(1,ABS(Bound)). If you need a very small value then your model is probably poorly scaled.
Range: [
3.e-13,1.e-5]Default:
1.e-7
RTBNDT (real): Bound tolerance for defining variables as fixed. ↵
A variable is considered fixed if the distance between the bounds is less than Rtbndt * Max(1,Abs(Bound)). The tolerance is also used on implied bounds (from converted inequalities) and these implied bounds may be infeasible up to Rtbndt.
Range: [
3.e-13,1.e-5]Default:
1.e-7
RTIPVA (real): Absolute Pivot Tolerance for building initial basis. ↵
Absolute pivot tolerance used during the search for a first logically non-singular basis. The default is fairly large to encourage a better conditioned initial basis.
Range: [
3.e-13,1.e-3]Default:
1.e-7
RTIPVR (real): Relative Pivot Tolerance for building initial basis ↵
Relative pivot tolerance used during the search for a first logically non-singular basis.
Range: [
1.e-4,0.9]Default:
1.e-3
RTMAXJ (real): Upper bound on the value of a function value or Jacobian element. ↵
Very large values of variables, function value, and derivatives and in particular large variations in the absolute value of the variables, functions, and derivatives makes the model harder to solve and poses problems for both feasibility and optimality tests. CONOPT will usually try to scale the model (see LSSCAL) to remove these problems. However, scaling can also make important aspects of a model appear un-important and there is therefore a limit to how aggressively we can scale a model (see RTMAXS and RTMINS). To avoid serious scaling problems CONOPT poses upper bounds on all variables (see RTMAXV) and all function value and derivatives, RTMAXJ.
Range: [
1.e4,1.e30]Default:
1.e10
RTMAXS (real): Upper bound on scale factors. ↵
Scale factors are projected on the interval from Rtmins to Rtmaxs. Is used to prevent very large or very small scale factors due to pathological types of constraints. RTMAXS is silently increased to max(RTMAXV,RTMAXS)/100 if RTMAXV or RTMAXJ have large non-default values.
Range: [
1,1.e20]Default:
1.e9
RTMAXV (real): Upper bound on solution values and equation activity levels ↵
See RTMAXJ for a discussion of why CONOPT poses upper bounds on variables and derivatives. If the value of a variable, including the objective function value, exceeds RTMAXV then the model is considered to be unbounded and the optimization process returns the solution with the large variable flagged as unbounded.
Range: [
1.e5,1.e30]Default:
1.e10
RTMINA (real): Zero filter for Jacobian elements and inversion results. ↵
Contains the smallest absolute value that an intermediate result can have. If it is smaller, it is set to zero. It must be smaller than RTPIVA/10.
Range: [
1.e-30, ∞]Default:
1.e-20
RTMINJ (real): Filter for small Jacobian elements to be ignored during scaling. ↵
A Jacobian element is considered insignificant if it is less than Rtminj. The value is used to select which small values are scaled up during scaling of the Jacobian.
Range: [
1.e-7,1.e-3]Default:
1.e-5
RTMINS (real): Lower bound for scale factors computed from values and 1st derivatives. ↵
Scale factors used to scale variables and equations are projected on the range Rtmins to Rtmaxs. The limits are used to prevent very large or very small scale factors due to pathological types of constraints. The default value for Rtmins is 1 which means that small values are not scaled up. If you need to scale small value up towards 1 then you must define a value of Rtmins < 1.
Range: [
1.e-10,1]Default:
1
RTMNS2 (real): Lower bound for scale factors based on large 2nd derivatives. ↵
Scaling of the model is in most cases based on the values of the variables and the first derivatives. However, if the scaled variables and derivatives are reasonable but there are large values in the Hessian of the Lagrangian (the matrix of 2nd derivatives) then the lower bound on the scale factor can be made smaller than Rtmins. CONOPT will try to scale variables with large 2nd derivatives by one over the square root of the diagonal elements of the Hessian. However, the revised scale factors cannot be less than Rtmns2.
Range: [
1.e-9,1]Default:
1.e-6
RTMXJ2 (real): Upper bound on second order terms. ↵
The function and derivative debugger (see LKDEBG) tests if derivatives computed using the modelers routine are sufficiently close to the values computed using finite differences. The term for the acceptable difference includes a second order term and uses RTMXJ2 as an upper bound on second order derivatives in the model. Larger RTMXJ2 values will allow larger deviations between the user-defined derivatives and the numerically computed derivatives.
Range: [
1, ∞]Default:
1.e4
RTNWMA (real): Maximum feasibility tolerance (after scaling). ↵
The feasibility tolerance used by CONOPT is dynamic. As long as we are far from the optimal solution and make large steps it is not necessary to compute intermediate solutions very accurately. When we approach the optimum and make smaller steps we need more accuracy. RTNWMA is the upper bound on the dynamic feasibility tolerance and RTNWMI is the lower bound.
Range: [
1.e-10,1.e-3]Default:
1.e-7
RTNWMI (real): Minimum feasibility tolerance (after scaling). ↵
See RTNWMA for a discussion of the dynamic feasibility tolerances used by CONOPT.
Range: [
4.e-11,1.e-5]Default:
4.e-10
RTNWTR (real): Feasibility tolerance for triangular equations. ↵
Triangular equations are usually solved to an accuracy of RTNWMI. However, if a variable reaches a bound or a constraint only has pre-determined variables then the feasibility tolerance can be relaxed to Rtnwtr.
Range: [
3.e-13,1.e-4]Default:
2.0e-8
RTOBJL (real): Limit for relative change in objective for well-behaved iterations. ↵
The change in objective in a well-behaved iteration is considered small and the iteration counts as slow progress if the change is less than Rtobjl * Max(1,Abs(Objective)). See also LFNICR.
Range: [
3.0e-13,1.0e-5]Default:
3.0e-12
RTOBJR (real): Relative accuracy of the objective function. ↵
It is assumed that the objective function can be computed to an accuracy of Rtobjr * max( 1, abs(Objective) ). Smaller changes in objective are considered to be caused by round-off errors.
Range: [
3.0e-14,10.e-6]Default:
3.0e-13
RTONED (real): Accuracy of One-dimensional search. ↵
The onedimensional search is stopped if the expected decrease in then objective estimated from a quadratic approximation is less than Rtoned times the decrease so far in this onedimensional search.
Range: [
0.05,0.8]Default:
0.2
RTPIVA (real): Absolute pivot tolerance. ↵
During LU-factorization of the basis matrix a pivot element is considered large enough if its absolute value is larger than Rtpiva. There is also a relative test, see RTPIVR.
Range: [
2.2e-16,1.e-7]Default:
1.e-10
RTPIVR (real): Relative pivot tolerance during basis factorizations. ↵
During LU-factorization of the basis matrix a pivot element is considered large enough relative to other elements in the column if its absolute value is at least Rtpivr * the largest absolute value in the column. Small values or Rtpivr will often give a sparser basis factorization at the expense of the numerical accuracy. The value used internally is therefore adjusted dynamically between the users value and 0.9, based on various statistics collected during the solution process. Certain models derived from finite element approximations of partial differential equations can give rise to poor numerical accuracy and a larger user-value of Rtpivr may help.
Range: [
1.e-3,0.9]Default:
0.05
RTPIVT (real): Absolute pivot tolerance for nonlinear elements in pre-triangular equations. ↵
The smallest pivot that can be used for nonlinear or variable Jacobian elements during the pre-triangular solve. The pivot tolerance for linear or constant Jacobian elements is Rtpiva. The value cannot be less that Rtpiva.
Range: [
2.2e-16,1.e-3]Default:
1.e-5
RTPIVU (real): Relative pivot tolerance during basis updates. ↵
During basischanges CONOPT attempts to use cheap updates of the LU-factors of the basis. A pivot is considered large enough relative to the alternatives in the column if its absolute value is at least Rtpivu * the other element. Smaller values of Rtpivu will allow sparser basis updates but may cause accumulation of larger numerical errors.
Range: [
1.e-3,0.9]Default:
0.05
RTPREC (real): Tolerance for printing variables changed by the pre-processor ↵
The list of variables changed by the pre-processor (see (PRPREC) ) can be limited to the variables that are changed by more than RTPREC, defined as deltaX > RTPREC * max(1, abs(X) ).
Range: [
0.0, ∞]Default:
0.0
RTPREL (real): Tolerance for defining large changes in variables in pre-processor ↵
The statistics for the number of variables that are changed in the pro-processor are classified as small and large changes. The change, DeltaX, is defined as large if deltaX > RTPREL * max(1, abs(X) ).
Range: [
0.0, ∞]Default:
0.01
RTREDG (real): Optimality tolerance for reduced gradient. ↵
The reduced gradient is considered zero and the solution optimal if the largest superbasic component of the reduced gradient is less than Rtredg.
Range: [
3.e-13,1]Default:
1.e-7
RTZERN (real): Zero-Noise in external equations ↵
By default CONOPT will debug the derivatives returned from External functions in GAMS in the initial point (see LKDEBG). If external functions have constant derivatives then the constant terms are still part of the external function and this can give rise to small inaccuracies in the contribution of the constant derivatives to the function value. This noise can cause the debugger to incorrectly state that a the external equation depend on the variable with the constant derivative. A larger value of Rtzern should remove the error.
Range: [
0.0,1]Default:
0.0
RVFILL (real): Fill in factor for basis factorization. ↵
Rvfill is used in the initial allocation of memory for the factorization of the basis. The fill-in (number of new nonzeros) is assumed to be Rvfill-1 times the initial number of nonzeros in the basis. The default is 5 but you may experiment with a smaller value (down to 1.0) for models that use too much memory to get started. If Rvfill is small you may get slower execution due to increased memory movement. And you may still run out of memory later in the optimization.
Range: [
1.00,20]Default:
5
RVHESS (real): Memory factor for Hessian generation: Skip if #Hessian elements > #Jacobian elements*Rvhess, 0 means unlimited. ↵
The Hessian of the Lagrangian is considered too dense and is not passed on to CONOPT if the number of nonzero elements in the Hessian of the Lagrangian is greater than the number of nonlinear Jacobian elements multiplied by Rvhess. The assumption is that a very dense Hessian is expensive both to compute and use. If Rvhess = 0.0 then there is no limit on the number of Hessian elements.
Default:
10
RVTIME (real): Time Limit. Overwrites the GAMS Reslim option. ↵
Synonym: reslim
The upper bound on the total number of seconds that can be used in the execution phase. There are only tests for time limit once per iteration. The default value is 10000. Rvtime is overwritten by Reslim when called from GAMS. Rvtime is defined in ProbSize and/or UpdtSize when used as a subroutine library.
Default:
GAMS ResLim
APPENDIX C: References
J. Abadie and J. Carpentier, Generalization of the Wolfe Reduced Gradient Method to the case of Nonlinear Constraints, in Optimization, R. Fletcher (ed.), Academic Press, New York, 37–47 (1969).
A. Drud, A GRG Code for Large Sparse Dynamic Nonlinear Optimization Problems, Mathematical Programming 31, 153–191 (1985).
A. S. Drud, CONOPT – A Large-Scale GRG Code, ORSA Journal on Computing 6, 207–216 (1992).
A. S. Drud, CONOPT: A System for Large Scale Nonlinear Optimization, Tutorial for CONOPT Subroutine Library, 16p, ARKI Consulting and Development A/S, Bagsvaerd, Denmark (1995).
A. S. Drud, CONOPT: A System for Large Scale Nonlinear Optimization, Reference Manual for CONOPT Subroutine Library, 69p, ARKI Consulting and Development A/S, Bagsvaerd, Denmark (1996).
J. K. Reid, A Sparsity Exploiting Variant of Bartels-Golub Decomposition for Linear Programming Bases, Mathematical Programming 24, 55–69 (1982).
D. M. Ryan and M. R. Osborne, On the Solution of Highly Degenerate Linear Programmes, Mathematical Programming 41, 385–392 (1988).
U. H. Suhl and L. M. Suhl, Computing Sparse LU Factorizations for Large-Scale Linear Programming Bases, ORSA Journal on Computing 2, 325–335 (1990).